tgoop.com/machinelearning_interview/1415
Last Update:
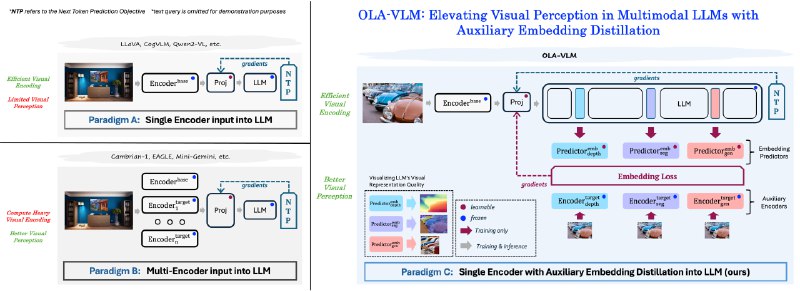
OLA-VLM - метод, который предлагает дистиллировать знания от визуальных энкодеров в противовес традиционному способу обучения MLLM.
В качестве целевых визуальных энкодеров были выбраны модели сегментации, оценки глубины и генерации изображений. На каждом слое LLM обучался проб, который должен прогнозировать выход соответствующего целевого энкодера.
Так архитектура OLA-VLM получила предикторы встраивания, которые получают токены из LLM и генерируют предсказания для вычисления потери встраивания. Эта потеря минимизируется вместе с потерей предсказания следующего токена.
Для улучшения восприятия целевой информации OLA-VLM использует специальные токены ⟨t⟩, которые добавляются к токенам изображения на входе LLM. Во время фазы настройки MLLM обучается только с использованием потери предсказания следующего токена. При этом специальные токены ⟨t⟩ остаются в входной последовательности, формируя неявную визуальную цепь рассуждений.
Эксперименты показали, что OLA-VLM превосходит модели семейства LLaVA-1.5 как по качеству визуальных представлений, так и по эффективности на различных тестах.
Методом OLA-VLM были обучены 12 моделей на LLMs Phi3-4K-mini и Llama3-8b с разными базовыми (ViT, CLIP-ConvNeXT) и целевыми (depth, segmentation, generation) энкодерами. Доступны версии PT (Pre-Training) и IFT (Instruction Fine-Tuning).
# Clone repo
git clone https://github.com/SHI-Labs/OLA-VLM
cd OLA-VLM
# Create conda env
conda create -n ola_vlm -y
conda activate ola_vlm
# Install dependencies
pip install -e .["demo"]
pip install flash-attn --no-build-isolation
pip install scikit-learn icecream datasets pytorch-fid lpips opencv-python-headless
pip install setuptools==61.0.0
pip install huggingface_hub==0.24.7
pip install transformers==4.41.1
# Run webUI with one of models
CUDA_VISIBLE_DEVICES=0 python demo.py --model-path %path_to_model% --PT-model-path %path_to_model%
@ai_machinelearning_big_data
#AI #ML #MMLM #OLA-VLM