tgoop.com/machinelearning_interview/1280
Last Update:
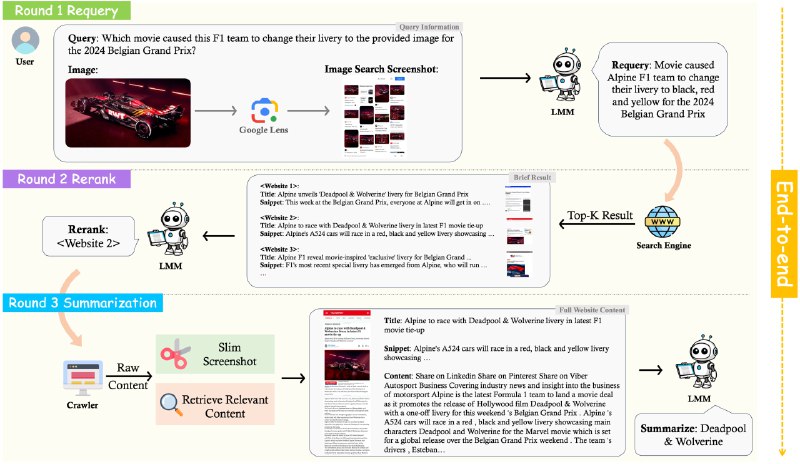
MMSearch — это тест мультимодального поиска, созданный для оценки возможностей LMMs как систем для поиска информации. Этот тест включает тщательно отобранный датасет из 300 запросов из 14 различных областей.
Чтобы обеспечить сложность бенчмарка, запросы классифицируются по двум основным категориям: новости и знания.
Область новостей состоит из недавних событий на момент сбора данных (август 2024 года), это гарантирует, что ответы на запросы не будут содержаться в обучающих данных для LMM.
В области знаний собраны запросы, требующие редких знаний - те, на которые не могут ответить современные LMM, такие как GPT-4o и Claude-3.5.
Оценка выполняется по 4 задачам, итог выполнения сравнивается с результатом аннотаторов, в роли которых выступали люди :
⚠️ Среднее время выполнения самого сложного теста (End-to-End) на одном GPU A100 - 3-5 часов.
Лидерборд MMSearch 16 моделей, включая результат выполнения тестов человеком можно посмотреть на странице проекта.
@ai_machinelearning_big_data
#AI #ML #MMLM #Benchmark