tgoop.com/data_math/583
Last Update:
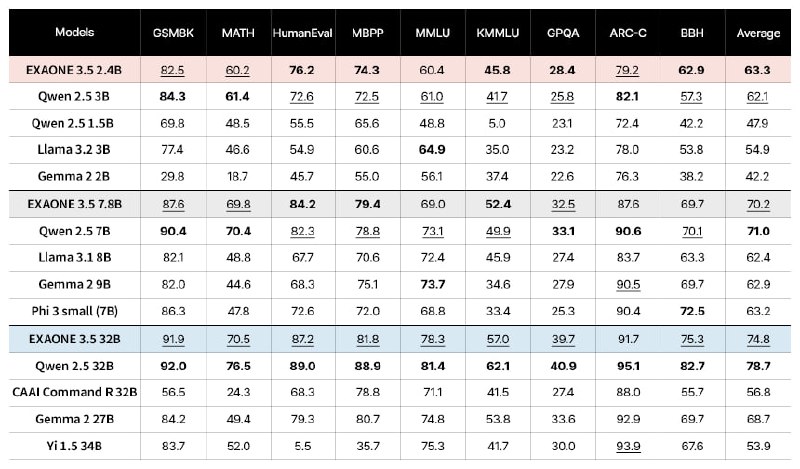
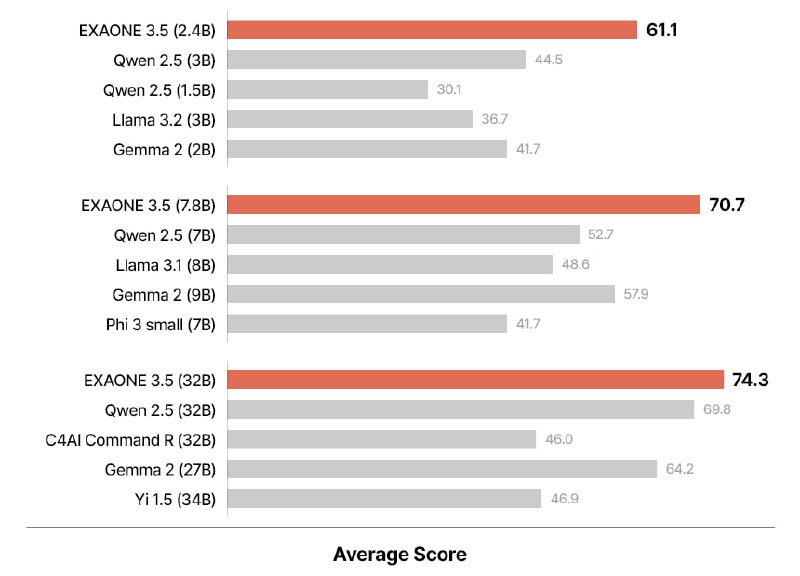
LG AI Research опубликовала 3 новые инструктивные двуязычные (английский и корейский) модели EXAONE 3.5 с контекстным окном в 32 тыс. токенов:
Разработчики EXAONE 3.5 улучшили эффективность обучения моделей. На этапе предварительного обучения из наборов данных удалялись дубликаты и личная информация, что позволило повысить качество ответов моделей и оптимизировать использование ресурсов. На этапе постобработки применялись методы SFT и DPO, чтобы улучшить способность моделей понимать инструкции и предпочтения пользователей.
Для повышения надежности оценки производительности EXAONE 3.5 был проведен тщательный процесс деконтаминации. Метод деконтаминации был взят из глобальной модели, а его эффективность оценивалась путем многократного сравнения обучающих данных с тестовыми наборами данных.
К каждой модели, LG AI выпустил квантованные версии в форматах AWQ и GGUF.
⚠️ EXAONE 3.5 - инструктивные модели, поэтому рекомендуется использовать системные промпты, представленные в примере кода инференса.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "LGAI-EXAONE/EXAONE-3.5-7.8B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "%Prompt%"
messages = [
{"role": "system", "content": "You are EXAONE model from LG AI Research, a helpful assistant."},
{"role": "user", "content": prompt}
]
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt"
)
output = model.generate(
input_ids.to("cuda"),
eos_token_id=tokenizer.eos_token_id,
max_new_tokens=128,
do_sample=False,
)
print(tokenizer.decode(output[0]))
@ai_machinelearning_big_data
#AI #ML #LLM #EXAONE #LG