⚡️ Qwen2-VL: второе поколение VLM моделей от Alibaba Cloud.
Qwen2-VL - это новая версия VLMs, основанная на Qwen2 в семействе моделей Qwen. По сравнению предыдущим поколением, Qwen2-VL обладает возможностями:
🟢Распознавание изображений с различным разрешением и соотношением сторон;
🟢VQA-понимание видеороликов продолжительностью более 20 минут с поддержкой диалога;
🟢Интеграция с носимыми устройствами (мобильный телефон, робот и т.д) в качестве агента управления;
🟢Мультиязычность внутри входных данных, например на изображениях или видео.
🟢Улучшенное распознавание объектов и предметов;
🟢Расширенные возможности в области математики и понимания программного кода.
Набор Qwen2-VL состоит из трех основных моделей, две из которых публикуются в отrрытом доступе. Модель Qwen2-VL-72B доступна только по
API:
🟠Qwen2-VL-72B;
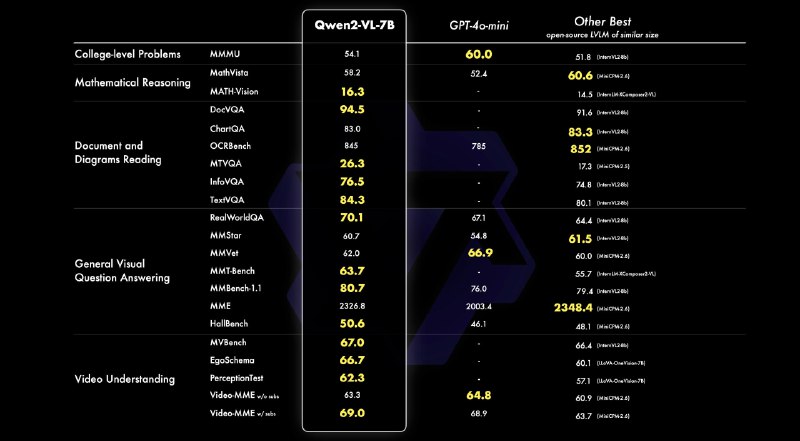
🟢Qwen2-VL-7B-Instruct;
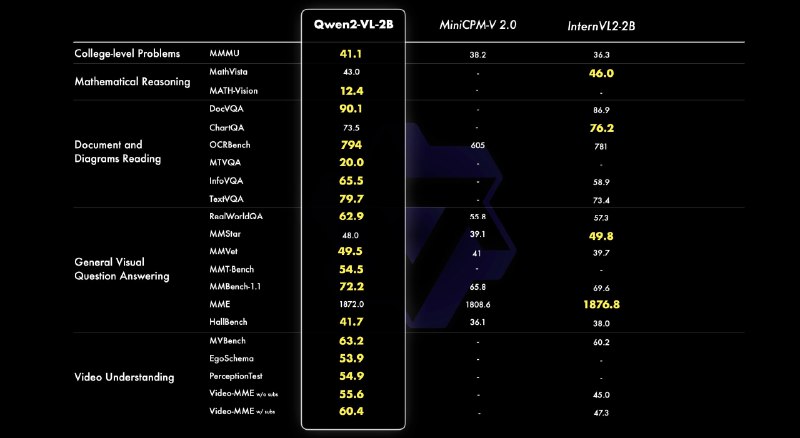
🟢Qwen2-VL-2B-Instruct,
и их квантованные версии в форматах
AWQ и GPTQ в разрядностях Int8 и Int4.
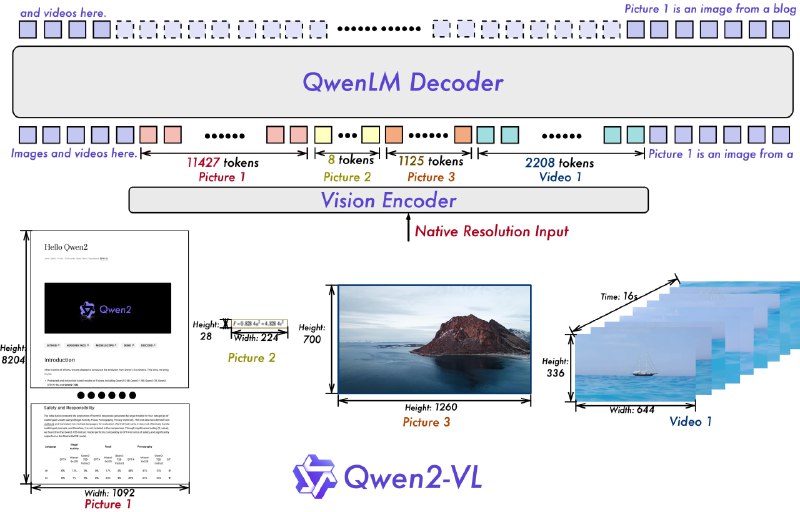
Архитектура моделей. как и в прошлом поколении основана на ViT 600M и LLM Qwen2, но с добавлением двух ключевых модификаций:
🟠использование NDR (Naive Dynamic Resolution), который позволил обрабатывать входные данные любого разрешения, преобразуя их в динамическое количество визуальных токенов. Эта реализация максимально близка к имитации зрительного восприятия человека.
🟠технология Multimodal Rotary Position Embedding (M-ROPE). Благодаря деконструкции оригинального rotary embedding на три части, представляющие временную и пространственную информацию, M-ROPE дает возможность LLM одновременно захватывать 1D( текст ), 2D( визуал ) и 3D( видео ) информацию.
⚠️ Ограничения в возможностях и слабые стороны поколения состоят в том, что модели не умеют извлекать звук из видео, а их знания актуальны на июнь 2023 года.
Кроме того, они не могут гарантировать полную точность при обработке сложных инструкций или сценариев. Модели относительно слабы в задачах, связанных со счетом, распознаванием символов и трехмерным пространственным восприятием.
▶️Использование и интеграция Qwen2-VL возможна с инструментами и на фреймворках:
Transformers, vLLM, Llama-Factory, AutoGPTQ, AutoAWQ.
📌Лицензирование: Apache 2.0 License.
🟡Страница проекта🟡Набор моделей🟡Demo🟡Сообщество в Discord🖥Github [ Stars: 59 | Issues: 3 | Forks: 2]
@ai_machinelearning_big_data#AI #Qwen #ML #GPTQ #VLM #AWQ