tgoop.com/data_math/411
Last Update:
DeepSeek-Prover-V1.5 - набор из языковых моделей для доказательства теорем в Lean 4.
"V1.5" означает обновление DeepSeek-Prover-V1 с некоторыми ключевыми нововведениями.
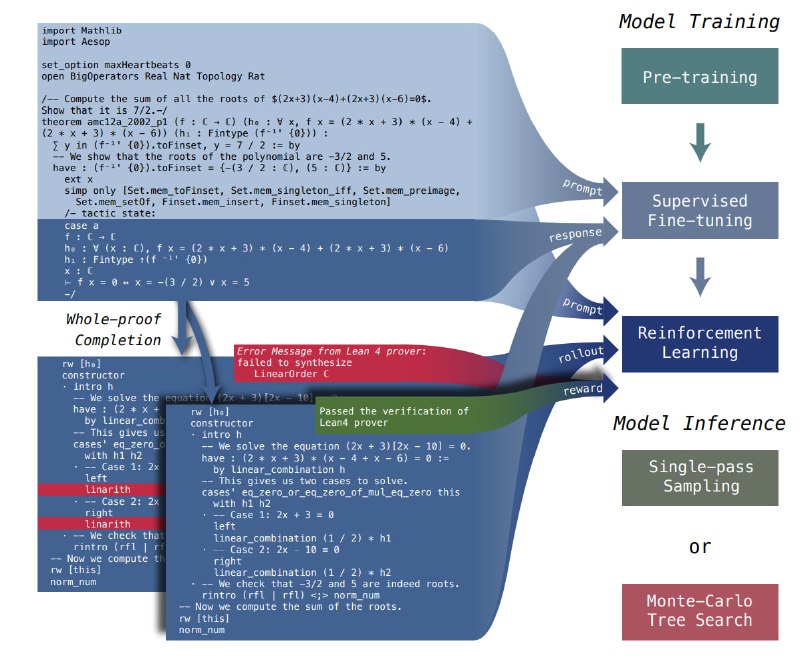
Во-первых, процесс обучения: предварительная подготовка на базе DeepSeekMath, затем контрольная работа с набором данных, включающим логические комментарии на естественном языке и код Lean 4. Это устраняет разрыв между рассуждениями на естественном языке и формальным доказательством теоремы. В набор данных также входит информация о промежуточном тактическом состоянии, которая помогает модели эффективно использовать обратную связь с компилятором.
Во-вторых, проводится обучение с подкреплением, используя алгоритм GRPO для изучения обратной связи с помощником по проверке. Тут выравнивается соответствие модели формальным спецификациям системы проверки.
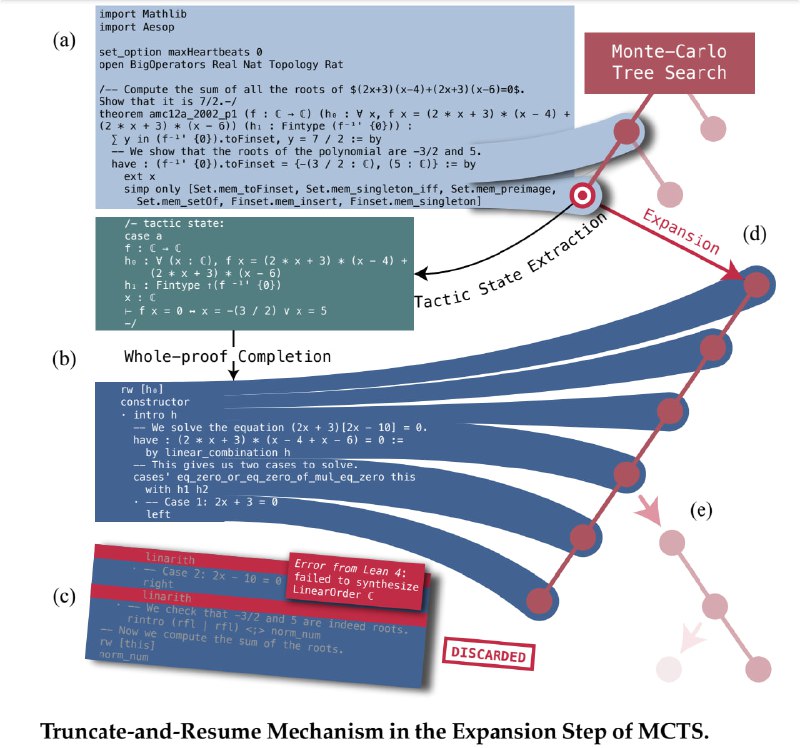
В-третьих, RMaxTS, варианте поиска в дереве по методу Монте-Карло. Он присваивает встроенные вознаграждения на основе изучения тактического пространства состояний, побуждая модель генерировать различные пути доказательства. Это приводит к более обширному исследованию пространства доказательств.
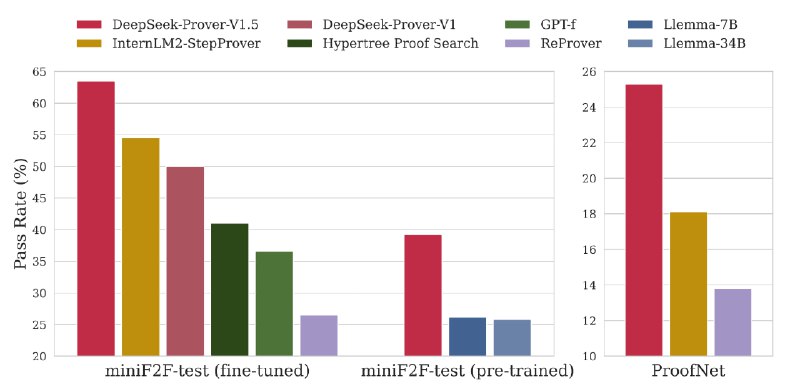
В результате получился набор моделей с абсолютной точностью генерации в 46,3% на тестовом наборе miniF2F. Этот показатель лучше, чем у GPT-4 и моделей RL, специализирующихся на доказательстве теорем.
Набор DeepSeek-Prover:
# Clone the repository:
git clone --recurse-submodules git@github.com:deepseek-ai/DeepSeek-Prover-V1.5.git
cd DeepSeek-Prover-V1.5
# Install dependencies:
pip install -r requirements.txt
# Build Mathlib4:
cd mathlib4
lake build
# Run paper experiments:
python -m prover.launch --config=configs/RMaxTS.py --log_dir=logs/RMaxTS_results
@ai_machinelearning_big_data
#AI #LLM #Math #ML