
Forwarded from Machinelearning
🚨 Grok 4 — новая мощная модель от xAI
📊 Лидер на бенчмарках:
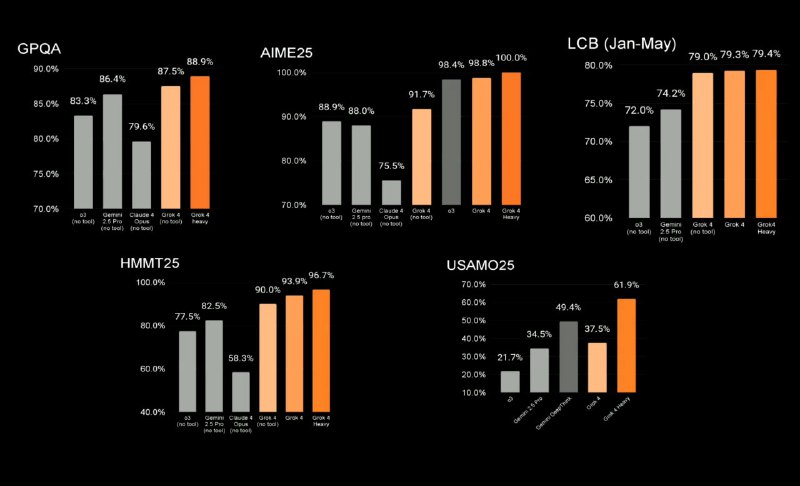
- Решает математику AIME25 на 100% — не ошиблась ни в одной из самых сложных задач
- ARC-AGI-2: 15.9% против 8.6% у прошлых лидеров — почти в два раза выше, чем у Claude 4 Opus.
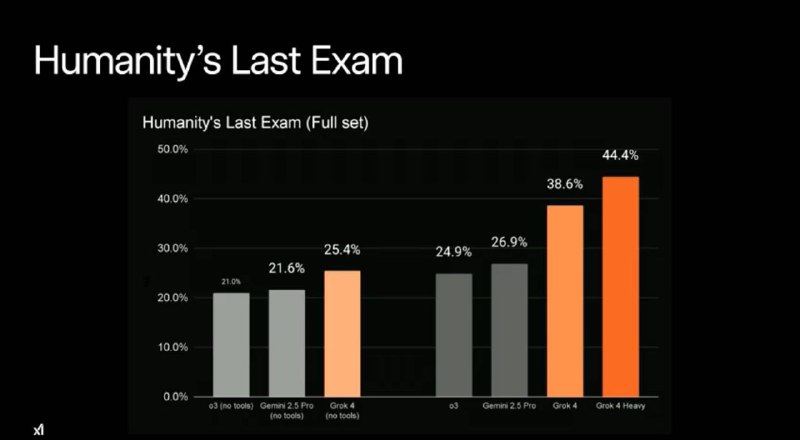
🧠 Главное достижение — Humanity’s Last Exam:
- С максимальными ресурсами и включённой поддержкой внешних инструментов — 44.4% (а на текстовой части даже 50.7%).
- Даже без внешних инструментов — всё ещё лучше всех: 25.4%, у ближайшего конкурента (Gemini 2.5 Pro) — 21.6%.
- Почти половина презентации была посвящена именно этому тесту.
🛠 Что под капотом:
- Архитектура — та же, что у Grok 3.
- Изначально это должна была быть версия Grok 3.5, но решили увеличить объём обучения.
- На стадию логического обучения (reasoning) потратили в 10 раз больше ресурсов.
- Теперь объём дообучения через RL (reinforcement learning) сопоставим с основным обучением.
- Важно: теперь модель сразу обучают использовать внешние инструменты во время RL, как это делают в OpenAI (в o3 и o4-mini).
📉 Слабые места:
- Мультимодальность пока на слабом уровне: большинство тестов — чисто текстовые, и на HLE модель показывает просадку.
- Маск пообещал, что в следующей версии это исправят.
📏 Контекст увеличили до 256k токенов.
💬 API уже запущен:
- Стоимость — как у Grok 3 и Claude Sonnet.
- Но из-за "разговорчивости" на практике модель по цене ближе к Claude Opus.
- Grok 4 Mini не выпустили — жаль, ведь Grok 3 Mini была отличной за свою цену.
🏭 Инфраструктура xAI растёт стремительно:
- Через 3–4 недели стартует тренировка видеомодели на 100k+ GPU GB200.
- В июне компания привлекла $10 млрд: половина — инвестиции, половина — в долг.
- В планах — новое расширение дата-центра Colossus.
📌 Grok 4 — это не просто обновление, а важный шаг вперёд в развитии reasoning-моделей и интеграции с внешними возможностями.
Тестим здесь.
@ai_machinelearning_big_data
#grok
📊 Лидер на бенчмарках:
- Решает математику AIME25 на 100% — не ошиблась ни в одной из самых сложных задач
- ARC-AGI-2: 15.9% против 8.6% у прошлых лидеров — почти в два раза выше, чем у Claude 4 Opus.
🧠 Главное достижение — Humanity’s Last Exam:
- С максимальными ресурсами и включённой поддержкой внешних инструментов — 44.4% (а на текстовой части даже 50.7%).
- Даже без внешних инструментов — всё ещё лучше всех: 25.4%, у ближайшего конкурента (Gemini 2.5 Pro) — 21.6%.
- Почти половина презентации была посвящена именно этому тесту.
🛠 Что под капотом:
- Архитектура — та же, что у Grok 3.
- Изначально это должна была быть версия Grok 3.5, но решили увеличить объём обучения.
- На стадию логического обучения (reasoning) потратили в 10 раз больше ресурсов.
- Теперь объём дообучения через RL (reinforcement learning) сопоставим с основным обучением.
- Важно: теперь модель сразу обучают использовать внешние инструменты во время RL, как это делают в OpenAI (в o3 и o4-mini).
📉 Слабые места:
- Мультимодальность пока на слабом уровне: большинство тестов — чисто текстовые, и на HLE модель показывает просадку.
- Маск пообещал, что в следующей версии это исправят.
📏 Контекст увеличили до 256k токенов.
💬 API уже запущен:
- Стоимость — как у Grok 3 и Claude Sonnet.
- Но из-за "разговорчивости" на практике модель по цене ближе к Claude Opus.
- Grok 4 Mini не выпустили — жаль, ведь Grok 3 Mini была отличной за свою цену.
🏭 Инфраструктура xAI растёт стремительно:
- Через 3–4 недели стартует тренировка видеомодели на 100k+ GPU GB200.
- В июне компания привлекла $10 млрд: половина — инвестиции, половина — в долг.
- В планах — новое расширение дата-центра Colossus.
📌 Grok 4 — это не просто обновление, а важный шаг вперёд в развитии reasoning-моделей и интеграции с внешними возможностями.
Тестим здесь.
@ai_machinelearning_big_data
#grok
❤11👍4🔥2🍌1
tgoop.com/data_analysis_ml/3810
Create:
Last Update:
Last Update:
🚨 Grok 4 — новая мощная модель от xAI
📊 Лидер на бенчмарках:
- Решает математику AIME25 на 100% — не ошиблась ни в одной из самых сложных задач
- ARC-AGI-2: 15.9% против 8.6% у прошлых лидеров — почти в два раза выше, чем у Claude 4 Opus.
🧠 Главное достижение — Humanity’s Last Exam:
- С максимальными ресурсами и включённой поддержкой внешних инструментов — 44.4% (а на текстовой части даже 50.7%).
- Даже без внешних инструментов — всё ещё лучше всех: 25.4%, у ближайшего конкурента (Gemini 2.5 Pro) — 21.6%.
- Почти половина презентации была посвящена именно этому тесту.
🛠 Что под капотом:
- Архитектура — та же, что у Grok 3.
- Изначально это должна была быть версия Grok 3.5, но решили увеличить объём обучения.
- На стадию логического обучения (reasoning) потратили в 10 раз больше ресурсов.
- Теперь объём дообучения через RL (reinforcement learning) сопоставим с основным обучением.
- Важно: теперь модель сразу обучают использовать внешние инструменты во время RL, как это делают в OpenAI (в o3 и o4-mini).
📉 Слабые места:
- Мультимодальность пока на слабом уровне: большинство тестов — чисто текстовые, и на HLE модель показывает просадку.
- Маск пообещал, что в следующей версии это исправят.
📏 Контекст увеличили до 256k токенов.
💬 API уже запущен:
- Стоимость — как у Grok 3 и Claude Sonnet.
- Но из-за "разговорчивости" на практике модель по цене ближе к Claude Opus.
- Grok 4 Mini не выпустили — жаль, ведь Grok 3 Mini была отличной за свою цену.
🏭 Инфраструктура xAI растёт стремительно:
- Через 3–4 недели стартует тренировка видеомодели на 100k+ GPU GB200.
- В июне компания привлекла $10 млрд: половина — инвестиции, половина — в долг.
- В планах — новое расширение дата-центра Colossus.
📌 Grok 4 — это не просто обновление, а важный шаг вперёд в развитии reasoning-моделей и интеграции с внешними возможностями.
Тестим здесь.
@ai_machinelearning_big_data
#grok
📊 Лидер на бенчмарках:
- Решает математику AIME25 на 100% — не ошиблась ни в одной из самых сложных задач
- ARC-AGI-2: 15.9% против 8.6% у прошлых лидеров — почти в два раза выше, чем у Claude 4 Opus.
🧠 Главное достижение — Humanity’s Last Exam:
- С максимальными ресурсами и включённой поддержкой внешних инструментов — 44.4% (а на текстовой части даже 50.7%).
- Даже без внешних инструментов — всё ещё лучше всех: 25.4%, у ближайшего конкурента (Gemini 2.5 Pro) — 21.6%.
- Почти половина презентации была посвящена именно этому тесту.
🛠 Что под капотом:
- Архитектура — та же, что у Grok 3.
- Изначально это должна была быть версия Grok 3.5, но решили увеличить объём обучения.
- На стадию логического обучения (reasoning) потратили в 10 раз больше ресурсов.
- Теперь объём дообучения через RL (reinforcement learning) сопоставим с основным обучением.
- Важно: теперь модель сразу обучают использовать внешние инструменты во время RL, как это делают в OpenAI (в o3 и o4-mini).
📉 Слабые места:
- Мультимодальность пока на слабом уровне: большинство тестов — чисто текстовые, и на HLE модель показывает просадку.
- Маск пообещал, что в следующей версии это исправят.
📏 Контекст увеличили до 256k токенов.
💬 API уже запущен:
- Стоимость — как у Grok 3 и Claude Sonnet.
- Но из-за "разговорчивости" на практике модель по цене ближе к Claude Opus.
- Grok 4 Mini не выпустили — жаль, ведь Grok 3 Mini была отличной за свою цену.
🏭 Инфраструктура xAI растёт стремительно:
- Через 3–4 недели стартует тренировка видеомодели на 100k+ GPU GB200.
- В июне компания привлекла $10 млрд: половина — инвестиции, половина — в долг.
- В планах — новое расширение дата-центра Colossus.
📌 Grok 4 — это не просто обновление, а важный шаг вперёд в развитии reasoning-моделей и интеграции с внешними возможностями.
Тестим здесь.
@ai_machinelearning_big_data
#grok
BY Анализ данных (Data analysis)
Share with your friend now:
tgoop.com/data_analysis_ml/3810