
tgoop.com/data_analysis_ml/3760
Last Update:
🧠 WM-Abench — бенчмарк для оценки памяти у мультимодальных LLM
Новый open-source бенчмарк от Maitrix Research оценивает, как мультимодальные модели (текст + изображение) запоминают и используют визуальную информацию.
📌 Что проверяется:
– Могут ли LLM “удерживать в голове” объекты, числа и расположение
– Насколько глубоко модель понимает визуальный контекст
– Способна ли она логически оперировать на основе того, что “видела”
📈 Поддерживаются: GPT‑4o, Gemini, Claude, LLaVA и другие
🔍 Задания: от простых “где лежит мяч?” до сложных визуальных рассуждений
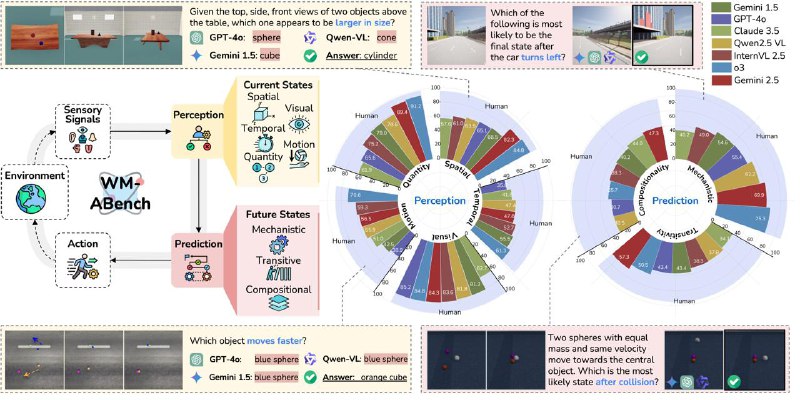
Исследователи из Maitrix оценили 15 SOTA мультимодальных моделей (включая o3 и Gemini 2.5 Pro) по 23 когнитивным измерениям: от базового восприятия до предсказания будущих состояний.
Ключевые выводы:
🔹 Модели хорошо справляются с распознаванием, но проваливаются в 3D-пространственном мышлении, динамике движения и причинно-следственной симуляции.
🔹 VLM склонны “путать” физику: даже изменение цвета объекта сбивает модель на задачах восприятия.
🔹 В сложных задачах предсказания следующего состояния — даже лучшие модели отстают от человека на 34.3%.
🔹 Точность восприятия ≠ понимание: даже “увидев” всё правильно, модели не умеют достроить последствия и взаимодействия объектов.
Отличный инструмент, чтобы понять на что реально способна ваша мультимодальная модель, а не только на красивые демо.
🔗 https://wm-abench.maitrix.org
#LLM #AI #multimodal #benchmark
BY Анализ данных (Data analysis)
Share with your friend now:
tgoop.com/data_analysis_ml/3760