tgoop.com/data_analysis_ml/3704
Last Update:
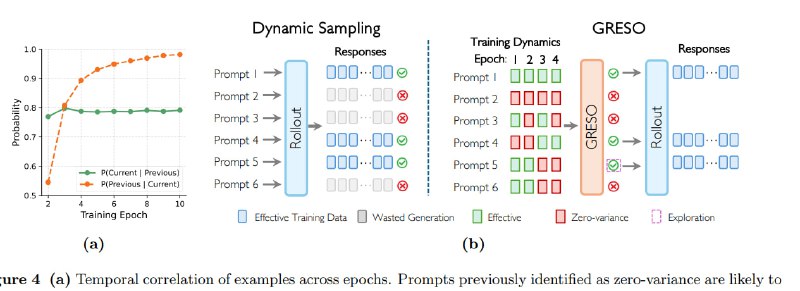
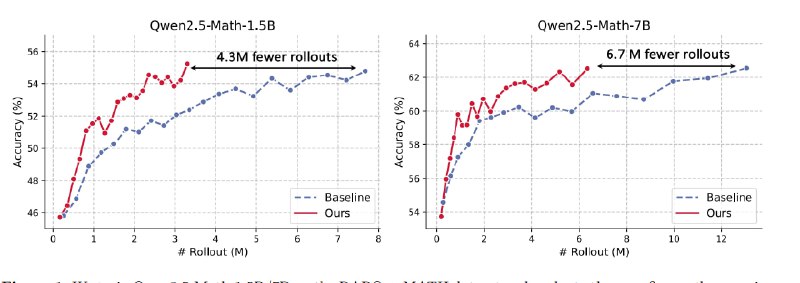
GRESO - это новый алгоритм для эффективного обучения с подкреплением больших языковых моделей, который сокращает вычислительные затраты на 40–60% без потери качества. Его суть в предварительной фильтрации «бесполезных» промптов, тех, что не дают модели обучаться, еще до дорогостоящей стадии rollout (генерации ответов модели).
В основе GRESO — вероятностная модель, предсказывающая, стоит ли прогонять промпт через LLM.
Алгоритм анализирует историю вознаграждений (reward dynamics) за прошлые эпохи обучения: если промпт много раз подряд давал идентичные награды на всех сгенерированных ответах (их называют zero-variance), он, скорее всего, бесполезен и сейчас.
GRESO не блокирует их жестко, он вычисляет вероятность пропуска , опираясь на число идущих подряд «пустых» прогонов и базовую вероятность «исследования». Это позволяет иногда перепроверять сложные промпты, на тот случай, если вдруг модель «доучилась» и теперь они полезны.
Базовая вероятность автоматически настраивается в реальном времени: если доля бесполезных промптов выше целевого значения (например, 25%), GRESO ее снижает, экономя ресурсы; если ниже — повышает, добавляя гибкости. Плюс, алгоритм разделяет промпты на легкие и сложные, применяя к ним разную политику исследования (сложные проверяет чаще, так как они перспективнее для обучения сильной модели).
А чтобы не гонять большие батчи ради пары примеров, размер выборки динамически подстраивается под текущие нужды на основе вычисления из недостающих данных, α — текущей доли пустых промптов и запаса надежности.
Хотя GRESO и экономит сотни часов на H100, делая RL-тюнинг доступнее, у него есть нюансы:Qwen Math 1.5В или Qwen Math 7b, есть несколько подготовленных скриптов файнтюна в train-scripts.
@ai_machinelearning_big_data
#AI #ML #LLM #RL #GRESO