tgoop.com/data_analysis_ml/3647
Last Update:
Apple внезапно опубликовала исследование, которое разоблачает популярные LLM с "цепочкой размышлений" (Chain-of-Thought) — такие как Gemini 2.5 Pro, OpenAI o3 и DeepSeek R1.
📌 Что тестировали?
Логические задачи:
• башни Ханоя (100+ шагов!)
• загадка про волка, козу и капусту
• головоломки с правилами и условиями
И всё это — с усложнением.
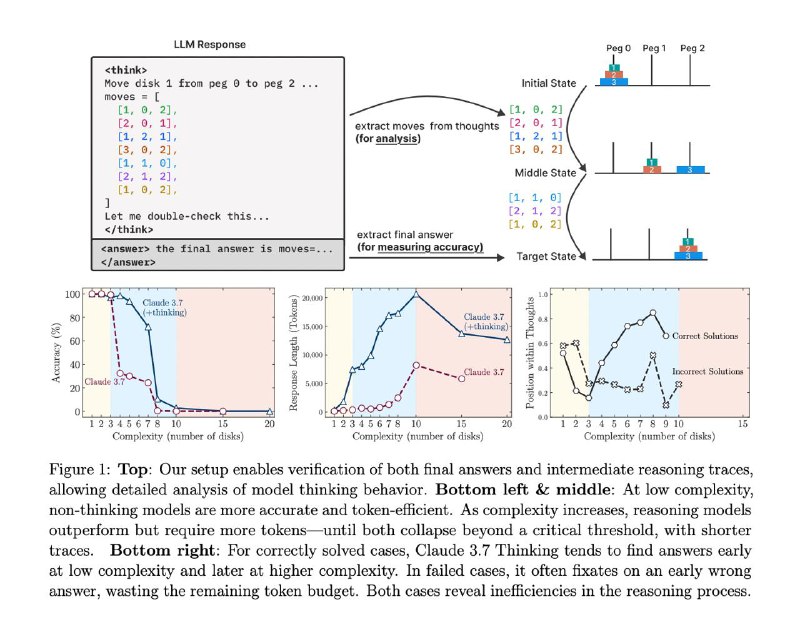
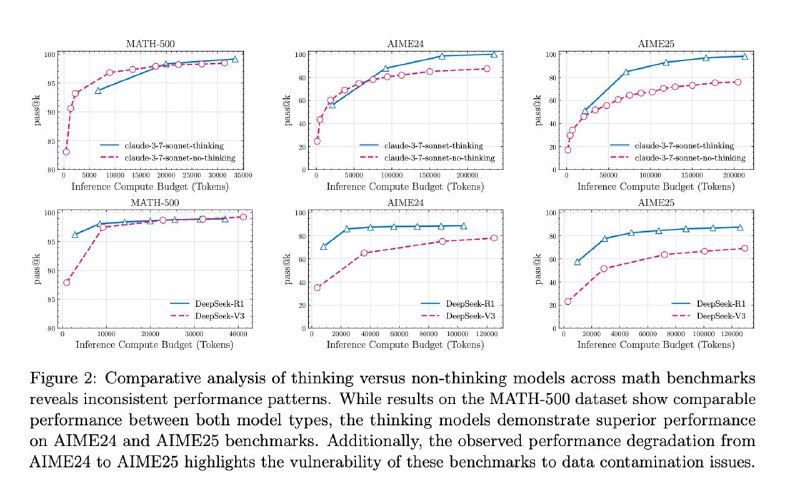
💥 Результаты:
— 🔁 Модели не думают, а вспоминают
Они не решают задачу шаг за шагом, а ищут похожие примеры в своей базе знаний. Это имитация мышления, а не само мышление.
— 🤯 "Переосмысление" вредит
Если задача простая, модель находит верный ответ — и… продолжает «думать» дальше, усложняя всё и случайно портя решение.
— 🧠 Больше размышлений ≠ лучше результат
Дать больше токенов и времени на размышления не помогает. На сложных задачах модели просто сдаются быстрее. Даже "бесконечный" бюджет не спасает.
— 🧪 Few-shot примеры не работают
Даже если расписать пошаговое решение и дать примеры — модель всё равно ломается, если задача ей незнакома.
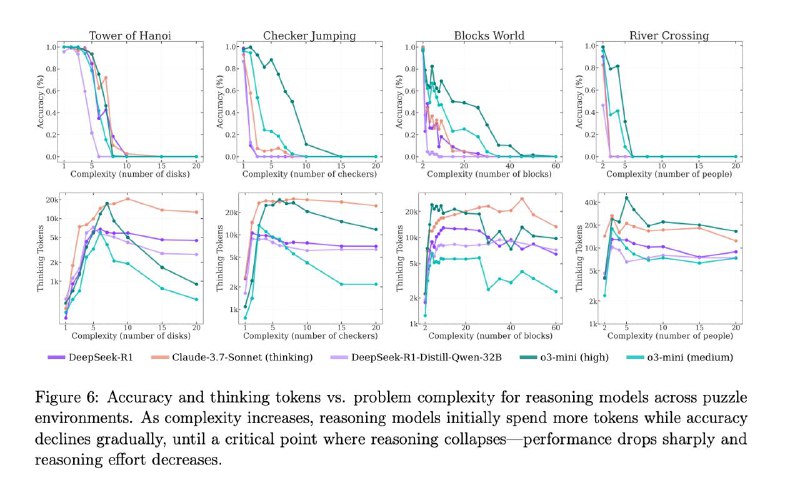
— 🏗 Модели обожают Ханой, но ненавидят загадки
Башни Ханоя решаются идеально даже на 100+ шагов.
А вот в простой задаче с козой и капустой — модели сдаются на 4-м шаге. Почему? Ханой — в датасетах, загадки про реку — нет.
🧠 Почему LLM не справляются с Ханойскими башнаями при большом числе дисков
Модели вроде Sonnet 3.7, DeepSeek R1 и o3-mini не могут правильно решать башни Ханоя, если дисков больше 13 — и вот почему:
📏 Немного математики:
• Чтобы решить башни Ханоя, нужно минимум 2ⁿ − 1 ходов
• Один ход — это примерно 10 токенов (формат: «переместить диск X с A на B»)
• А значит, для 15 дисков нужно ~**327,670 токенов** только на вывод шагов
🧱 Лимиты моделей:| Модель | Лимит токенов | Макс. число дисков (без размышлений) |
|--------------|----------------|---------------------------------------|
| DeepSeek R1 | 64k | 12
| o3-mini | 100k | 13
| Sonnet 3.7 | 128k | 13
И это без учёта reasoning (внутренних размышлений), которые модель делает перед финальным ответом.
🔍 Что реально происходит:
• Модели не могут вывести все шаги, если дисков слишком много
• При >13 дисках они просто пишут что-то вроде:
> *"Из-за большого количества шагов я опишу метод, а не приведу все 32 767 действий..."*
• Некоторые модели (например, Sonnet) перестают "думать" уже после 7 дисков — они просто описывают алгоритм и переходят к финальному ответу без вычислений
🎲 А теперь представим, что модель угадывает каждый шаг с точностью 99.99%
На задаче с 15 дисками (32767 ходов) ошибка почти неизбежна — чистая математика:
даже 0.01% ошибок на токенах *экспоненциально* накапливаются
🍏 Интересно, что Apple выпустила это исследование за день до WWDC 2025.
Подколка конкурентам? А завтра, может, и своё покажут. 🤔
📎 Исследование: https://ml-site.cdn-apple.com/papers/the-illusion-of-thinking.pdf
@data_analysis_ml
#AI #LLM #AGI #Apple #WWDC2025 #PromptEngineering #NeuralNetworks