
tgoop.com/data_analysis_ml/3606
Last Update:
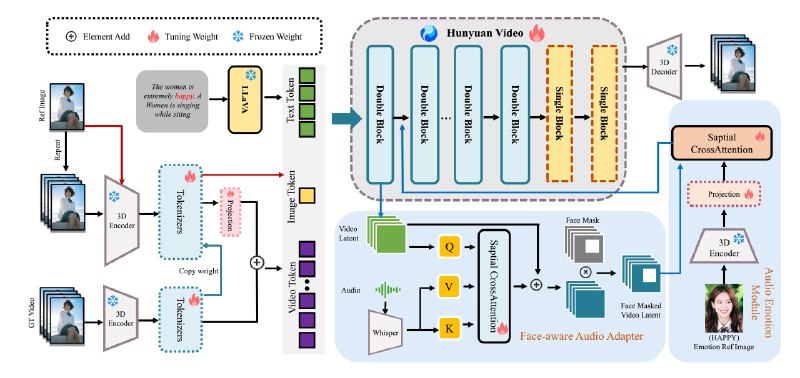
Вслед за релизом Hunyuan Portrait, Tencent выпустила Hunyuan Video Avatar - систему на базе MM-DiT для генерации динамичных видео из изображения с одним или несколькими персонажами, синхронизированных с аудио.
Объединить такие возможности было непростой задачей, это стало возможным благодаря использованию ключевых для Hunyuan Video Avatar методов:
По сравнительных тестах с Sonic, EchoMimic, EchoMimicV2 и Hallo-3 на датасетах для портретной анимации (HDTF, CelebV-HQ и свой приватный сет) Hunyuan Video Avatar показал лучшие результаты: 3,99 в метриках качества видео (IQA), 2,54 по эстетике (ASE), 5,30 в синхронизации аудио и видео (Sync-C), 38.01 в точности воспроизведения видео (FID) и 358.71 по искажениям (FVD).
При тестировании полнокадровой анимации на собственном датасете HunyuanVideo-Avatar показал лучшие результаты по IQA (4.66), ASE (3.03) и Sync-C (5.56) в сравнении с Hallo3, FantasyTalking и OmniHuman-1.
⚠️ Модель прожорливая: минимум 24 ГБ VRAM для 704x768, а для плавного 4K рекомендуют GPU на 96 ГБ.
Зато входные изображения берет любые: фотореалистичные портреты, 3D-модели, аниме-персонажи — хоть лису в костюме. Разрешение тоже гибкое: от крупных планов до полноростовых.
@ai_machinelearning_big_data
#AI #ML #HunyuanAvatar
{kind=link}