
🧠 VLM-3R: Мультимодальный агент нового поколения
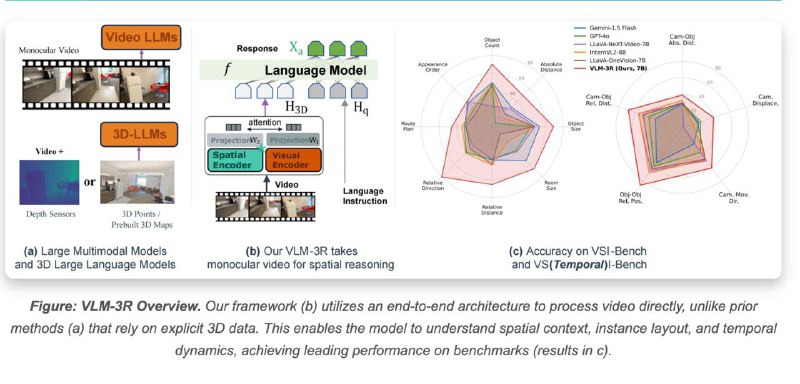
VLM-3R — это мощный мультимодальный агент, сочетающий визуальное восприятие, речевое взаимодействие и пространственное мышление.
🔍 Расшифровка названия:
VLM-3R = Vision-Language Model for **R**easoning, **R**econstruction и **R**eal-world interaction
🎯 Основные возможности:
• Понимание и генерация изображений, видео и речи
• Работа в 3D-пространствах (реконструкция и навигация)
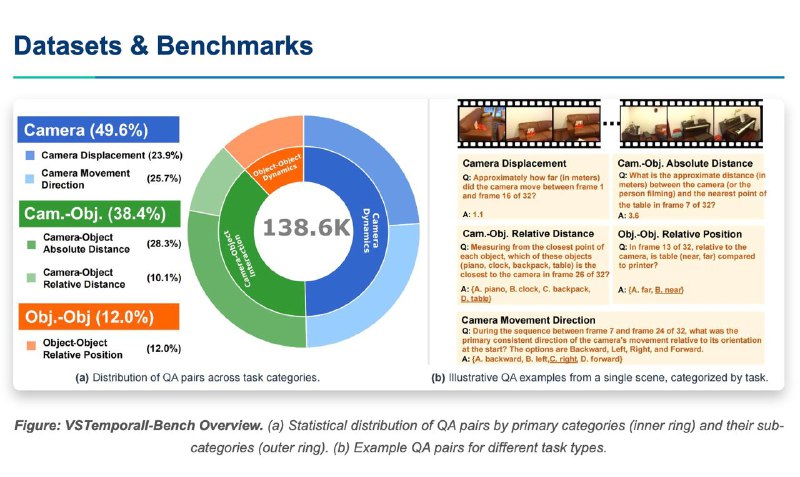
• Решение задач с реальным контекстом (например, манипуляции с объектами в симуляциях)
• Интерактивный агент с мультимодальной памятью и планированием
🚀 На чём построен:
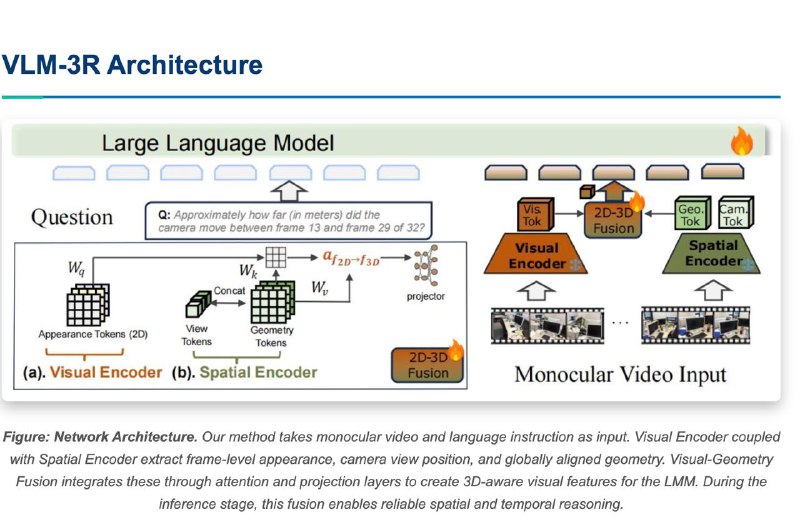
• VLM-3R интегрирует крупные языковые и визуальные модели
• Использует mid-level представления для более точного понимания
• Работает с 2D и 3D сценами, распознаёт объекты, действия и голосовые команды
🔬 Применения:
• Робототехника
• Виртуальные ассистенты
• Интерактивные обучающие среды
• Моделирование поведения в симулированных мирах
📎 Подробнее: https://vlm-3r.github.io/
VLM-3R — это мощный мультимодальный агент, сочетающий визуальное восприятие, речевое взаимодействие и пространственное мышление.
🔍 Расшифровка названия:
VLM-3R = Vision-Language Model for **R**easoning, **R**econstruction и **R**eal-world interaction
🎯 Основные возможности:
• Понимание и генерация изображений, видео и речи
• Работа в 3D-пространствах (реконструкция и навигация)
• Решение задач с реальным контекстом (например, манипуляции с объектами в симуляциях)
• Интерактивный агент с мультимодальной памятью и планированием
🚀 На чём построен:
• VLM-3R интегрирует крупные языковые и визуальные модели
• Использует mid-level представления для более точного понимания
• Работает с 2D и 3D сценами, распознаёт объекты, действия и голосовые команды
🔬 Применения:
• Робототехника
• Виртуальные ассистенты
• Интерактивные обучающие среды
• Моделирование поведения в симулированных мирах
📎 Подробнее: https://vlm-3r.github.io/
👍6❤5🔥2
tgoop.com/data_analysis_ml/3603
Create:
Last Update:
Last Update:
🧠 VLM-3R: Мультимодальный агент нового поколения
VLM-3R — это мощный мультимодальный агент, сочетающий визуальное восприятие, речевое взаимодействие и пространственное мышление.
🔍 Расшифровка названия:
VLM-3R = Vision-Language Model for **R**easoning, **R**econstruction и **R**eal-world interaction
🎯 Основные возможности:
• Понимание и генерация изображений, видео и речи
• Работа в 3D-пространствах (реконструкция и навигация)
• Решение задач с реальным контекстом (например, манипуляции с объектами в симуляциях)
• Интерактивный агент с мультимодальной памятью и планированием
🚀 На чём построен:
• VLM-3R интегрирует крупные языковые и визуальные модели
• Использует mid-level представления для более точного понимания
• Работает с 2D и 3D сценами, распознаёт объекты, действия и голосовые команды
🔬 Применения:
• Робототехника
• Виртуальные ассистенты
• Интерактивные обучающие среды
• Моделирование поведения в симулированных мирах
📎 Подробнее: https://vlm-3r.github.io/
VLM-3R — это мощный мультимодальный агент, сочетающий визуальное восприятие, речевое взаимодействие и пространственное мышление.
🔍 Расшифровка названия:
VLM-3R = Vision-Language Model for **R**easoning, **R**econstruction и **R**eal-world interaction
🎯 Основные возможности:
• Понимание и генерация изображений, видео и речи
• Работа в 3D-пространствах (реконструкция и навигация)
• Решение задач с реальным контекстом (например, манипуляции с объектами в симуляциях)
• Интерактивный агент с мультимодальной памятью и планированием
🚀 На чём построен:
• VLM-3R интегрирует крупные языковые и визуальные модели
• Использует mid-level представления для более точного понимания
• Работает с 2D и 3D сценами, распознаёт объекты, действия и голосовые команды
🔬 Применения:
• Робототехника
• Виртуальные ассистенты
• Интерактивные обучающие среды
• Моделирование поведения в симулированных мирах
📎 Подробнее: https://vlm-3r.github.io/
BY Анализ данных (Data analysis)
Share with your friend now:
tgoop.com/data_analysis_ml/3603