
tgoop.com/data_analysis_ml/3591
Last Update:
🧠 GAIA — новый ориентир для General AI Assistants
GAIA — это benchmark, который проверяет, насколько AI-ассистенты могут мыслить, действовать и работать с инструментами в реальных.
📊 Что тестируется
- 466 заданий, требующих:
- логического мышления и планирования
- работы с вебом и мультимодальностью (текст, изображения)
- использования инструментов — браузера, кода, анализа файлов и пр.
- Задания просты для человека, но AI решает их с трудом (люди получают ~92 %, GPT‑4 + плагины — ~15 %)
🔍 Почему это важно
- В отличие от других benchmark-ов, GAIA фокусируется на настоящих задачах, а не узкоспециализированных тестах
- Задания ясны и дают однозначный ответ, что облегчает автоматическую оценку
- Benchmark защищён от «запоминания» — задачи редко встречаются в открытых данных и требуют последовательных действий
🛠️ Как работает
1. Задачи задаются "в ноль" — без примеров
2. AI получает вопрос (текст и/или файл) и должен самостоятельно:
- искать в интернете
- обрабатывать мультимодальные данные
- выполнять код или анализ
3. Ответы оцениваются автоматически — только один правильный вариант
⚡ Перспективы и вызовы
- Пока лишь немногие модели приближаются к человеческому уровню — GPT‑4 с плагинами на ~15 %
- Benchmark рассчитан на долгосрочное развитие AGI — от точности решения до открытости и надёжности оценивания
- GAIA подчёркивает необходимость создания систем, способных последовательно действовать, а не просто «угадывать» ответы.
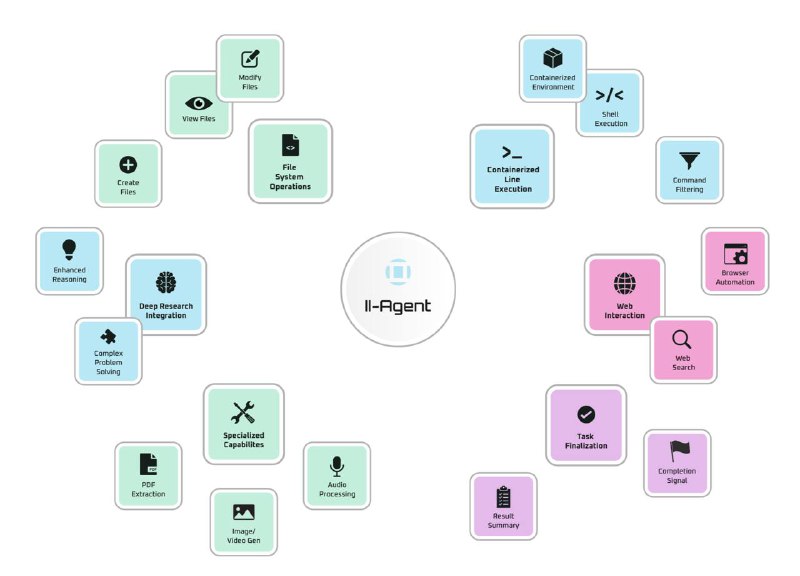
🔗 Github: https://github.com/Intelligent-Internet/ii-agent
🔗 GAIA Examples: https://ii-agent-gaia.ii.inc
BY Анализ данных (Data analysis)
Share with your friend now:
tgoop.com/data_analysis_ml/3591