tgoop.com/data_analysis_ml/3431
Last Update:
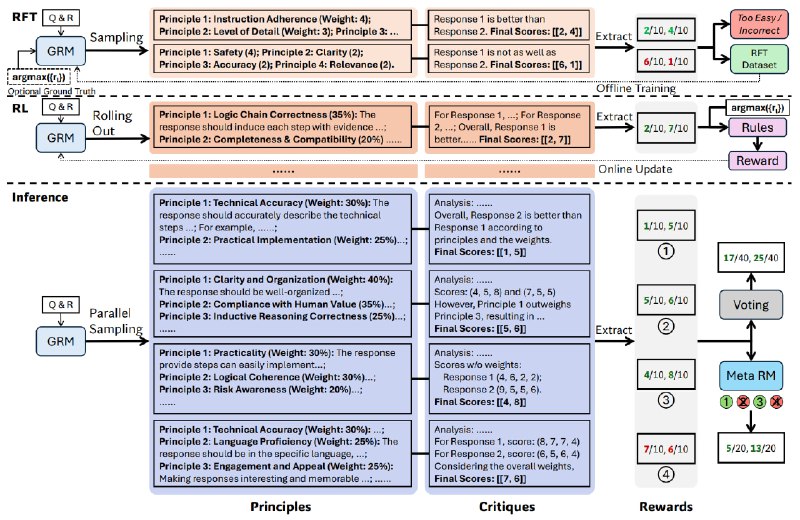
DeepSeek-AI и Университет Цинхуа опубликовали исследование о методе Self-Principled Critique Tuning (SPCT), который значительно повышает эффективность генеративных моделей вознаграждения (GRM) для больших языковых моделей. SPCT решает ключевую проблему RL-обучения — получение точных сигналов вознаграждения в условиях разных и неоднозначных задач, где нет четких правил или эталонов.
SPCT — это комбинация rejective fine-tuning и обучения с подкреплением на основе правил. Rejective fine-tuning учит модель генерировать принципы и критические оценки, адаптируясь к разным типам входных данных, а rule-based RL — оптимизирует процесс через систему поощрений, которая штрафует за ошибки в ранжировании ответов.
Это позволяет GRM самостоятельно создавать критерии оценки и точнее определять лучшие ответы в сложных сценариях, например, при работе с математическими задачами или этическими дилеммами.
Главное преимущество SPCT — масштабируемость инференса. Вместо увеличения размера модели авторы предлагают параллельно генерировать множество вариантов принципов и оценок, а затем агрегировать их через голосование. Чтобы фильтровать «шумные» варианты используется мета-модель вознаграждения, которая отбирает только качественные сэмплы.
По результатам тестов, DeepSeek-GRM с 27 млрд. параметров при 32 параллельных сэмплах превзошла 671B модель, демонстрируя, что вычислительные ресурсы можно эффективно распределять во время инференса, а не обучения.
Эксперименты на бенчмарках Reward Bench, PPE и RMB показали, что SPCT снижает предвзятость моделей. Например, в задачах на рассуждение точность выросла на 12%, а в оценке безопасности — на 9%. При этом метод сохраняет гибкость: одна и та же модель может оценивать одиночные ответы, пары или целые наборы, что критично для реальных приложений вроде чат-ботов или автономных систем.
К сожалению, идеальных решений не бывает и у метода есть существенное ограничение - GRM требуют больше вычислительных ресурсов, чем классические скалярные модели, а в узкоспециализированных областях (например, верификация кода) их точность пока уступает конкурентам.
@ai_machinelearning_big_data
#AI #ML #LLM #GRM #DeepSeekAI