tgoop.com/cpu_design/245
Last Update:
Драфт спецификации для матричного расширения RISC-V архитектуры.
Zvmm Family of Integrated Matrix Extensions, Version 0.1
IME — обозначает, что инструкции для работы с матрицами переиспользуют векторный регистровый файл, и данное расширение зависит от наличия и конфигурации векторного расширения.
Из интересных особенностей:
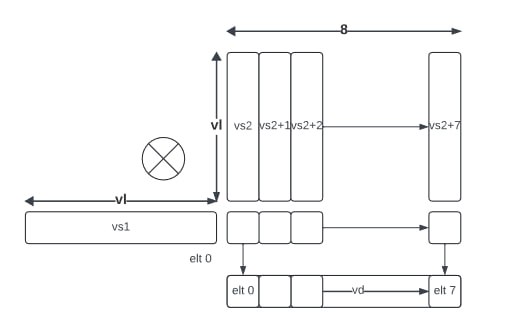
1) Новые инструкции для load/store не введены, вместо этого используются существующие векторные инструкции, такие как vle. Это позволяет избежать необходимости в изменении LSU pipeline и упрощает работу с памятью.
2) Выбран подход умножение вектора на матрицу, а не матрицу на матрицу, для упрощения аппаратуры, и как было указано выше, чтобы не усложнять LSU pipeline имплементацией более эффективных инструкций загрузки-сохранения матриц, а так же чтобы не раздвувать вычислительное ядро умножителями и деревом редукции частичных произведений.
Насколько это упрощение ценно и необходимо - вопрос открытый.
3) Zvmm32a16bf — в этом подмножестве анонсирована поддержка BF16, что оптимально для задач машинного обучения. Однако пока что не представлена поддержка FP16, что может стать предметом обсуждения для будущих версий.
4) Zvmm32a8mxf - поддержка 8-битных OCP MX типов данных, но не описана логика по работе с shared exponent.
5) Bulk normalization. Один из методов для проектирования матричного умножителя с плавающей точкой — использование bulk normalization. Этот подход предполагает динамическое выравнивание операндов относительно максимальной экспоненты в наборе, что позволяет значительно сократить аппаратные ресурсы.
Другой подход это конвертация float-point операндов в fixed point представлении. Этот подход дает бóльшую точность, избавляет от необходимости ранней нормализации, но намного затратнее с точки зрения аппаратуры.
Описание fixed-point подхода можно найти в данной статье.
Напоминаю, что это только драфт и многое еще может измениться