
tgoop.com/cpu_design/188
Last Update:
31st IEEE International Symposium on Computer Arithmetic ARITH 2024
В Испании прошел 31-й симпозиум по компьютерной арифметике. На конференции было представлено много интересных докладов, которые мы разберем в следующих постах.
Сегодня остановимся на докладе от ARM Fused FP8 4-Way/2-Way Dot Product With Scaling and FP32/FP16 Accumulation.
В докладе и статье описаны подходы, которые применялись при разработке SIMD умножителя с накоплением (матричного умножителя) — базовый блок в дизайне любого NPU/TSU ускорителя.
В работе представлен дизайн с FP8 двух типов +/-e5m2, +/-e4m3, etc (IEEE P3109) в двух имплементациях с ранним (EA) и поздним (LA) аккумулированием результата.
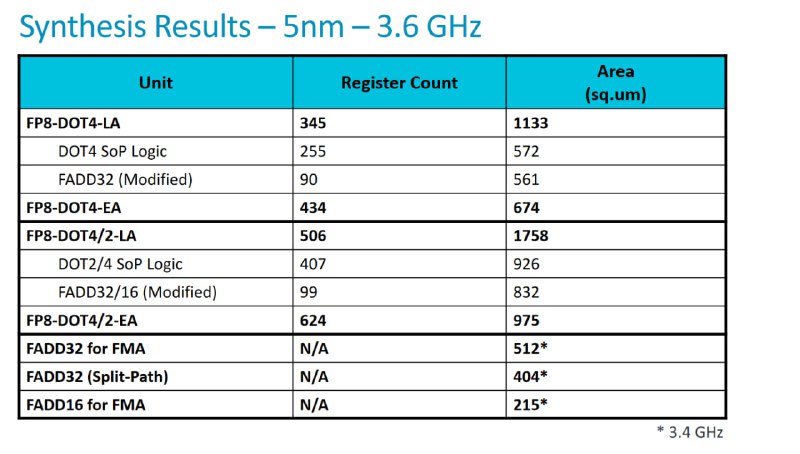
Обе микроархитектуры имеют конвейерное построение с четырьмя этапами для достижения целевой частоты 3,6 ГГц.
Подходы, предложенные авторами статьи, были синтезированы на базе 5-нм технологии. На основе полученных результатов синтеза авторы делают следующие предложение по использованию подходов с ранним и поздним аккумулированием в вычислительных системах:
FP8-DOT4-LA можно адаптировать для высокопроизводительных вычислительных блоков CPU с уже существующими блоками fma32, поскольку данный подход обеспечивает прирост производительности при минимальных дополнительных затратах в площади целевого дизайна.
FP8-DOT4-EA лучше подходит для специализированных ускорителей, где важно снизить общую площадь вычислительного юнита, что полезно при масштабировании вычислительных блоков.
Для более детального ознакомления с работой рекомендую обратиться к статье David R. Lutz.
ссылка на материалы конференции https://www.ac.uma.es/arith2024/program.html
ссылка на презентацию от ARM: https://www.ac.uma.es/arith2024/slides/3_ARITH-2024.paper45.pdf
BY Записки CPU designer'a
Share with your friend now:
tgoop.com/cpu_design/188