tgoop.com/ai_machinelearning_big_data/6968
Last Update:
Instella - полностью опенсорсная модель с 3 млрд. параметров, обученная с нуля на GPU AMD Instinct MI300X. Instella не только превосходит существующие LLM сопоставимого размера, но и показывает конкурентоспособную производительность по сравнению с Llama-3.2-3B, Gemma-2-2B и Qwen-2.5-3B.
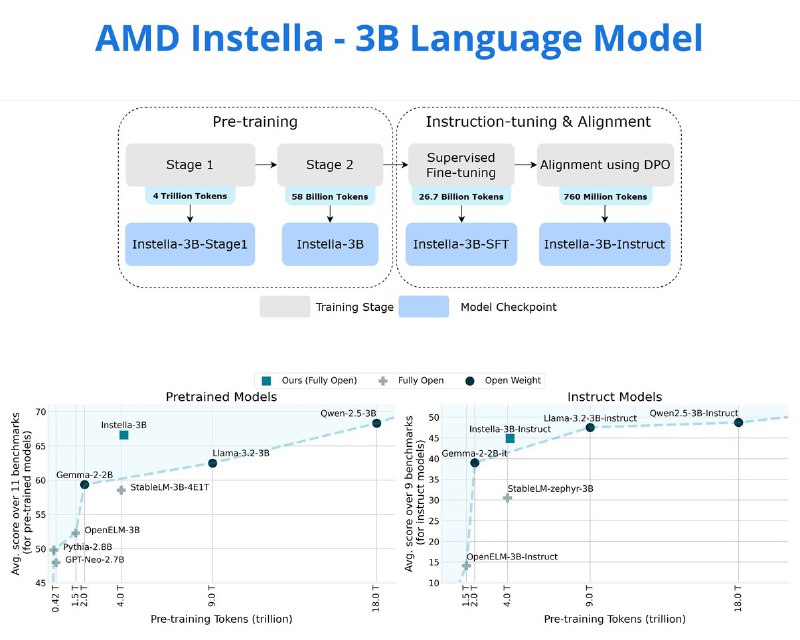
Разработка Instella основана на опыте AMD с OLMo, на которой была доказана возможность обучения LLM на стеке AMD. В процессе создания Instella прошлые наработки были масштабированы для создания модели с 3 млрд. параметров. Она обучалась на 128 GPU MI300X с использованием 4,15 трлн. токенов. В процессе применялись методы FlashAttention-2, Torch Compile и FSDP с гибридным шардированием.
Процесс обучения Instella состоял из 4-х этапов, постепенно наращивая возможности модели от базового понимания естественного языка до следования инструкциям и соответствия предпочтениям человека.
Первый этап претрейна задействовал 4 трлн. токенов из набора данных OLMoE-mix-0924 (код, академические тексты, математика и общие знания). Второй этап - 57 млрд. токенов из датасетов Dolmino-Mix-1124 и SmolLM-Corpus (python-edu).
На третьем этапе проводилась SFT модели с использованием 8,9 млрд. токенов текстовых пар "инструкция-ответ". Наконец, для приведения модели в соответствие с предпочтениями человека был выполнен четвертый этап - DPO модели Instella-3B-SFT с использованием 0,76 млрд токенов.
Instella получила 36 слоев, каждый из которых имеет 32 attention heads и поддерживает длину последовательности до 4096 токенов.
Финальный вариант Instella-3B превосходит существующие открытые модели в среднем на 8,08%.
@ai_machinelearning_big_data
#AI #ML #LLM #RoCM #AMD #Instella