tgoop.com/ai_machinelearning_big_data/6374
Last Update:
POINTS1.5 - усовершенствованная версия VLM POINTS1.0, построенная по принципу LLaVA (визуальный энкодер+LLM) на базе Qwen2.5-7B-Instruct.
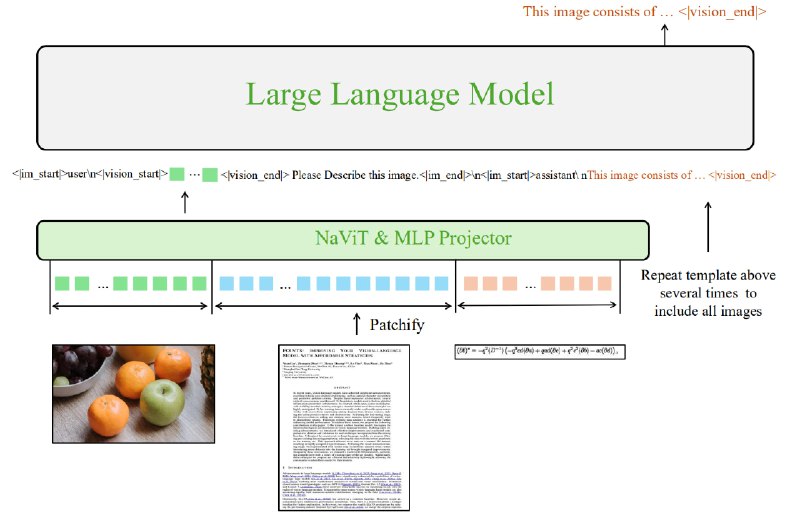
В отличие от предыдущей версии, где использовался энкодер изображений CLIP, POINTS1.5 использует энкодер NaViT, который позволяет модели обрабатывать изображения различного разрешения без необходимости их разделения.
Для повышения качества модели были применены методы фильтрации данных для обучения. Данные, не требующие анализа изображения для ответа на вопрос и содержащие грамматические ошибки, были удалены.
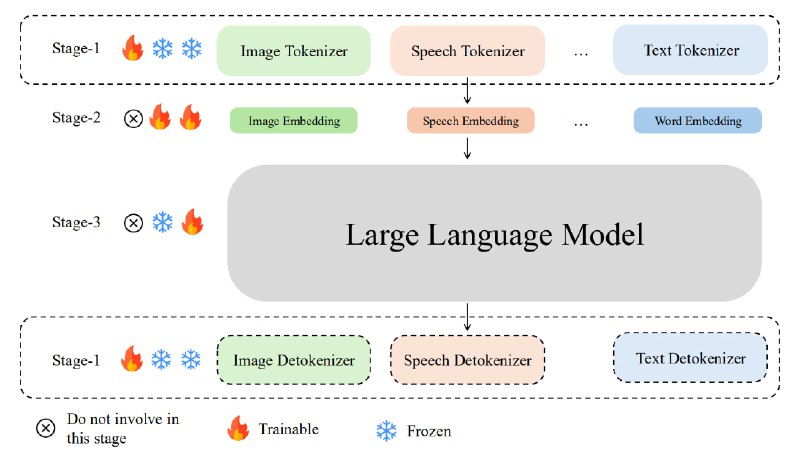
Обучение POINTS1.5 выполнялось в два этапа: предварительное обучение и настройка на выполнение визуальных инструкций. На этапе предварительного обучения проектор и LLM обучались совместно.
На этапе настройки на выполнение визуальных инструкций использовались специализированные наборы данных, которые обучают модель понимать инструкции, связанные с изображениями.
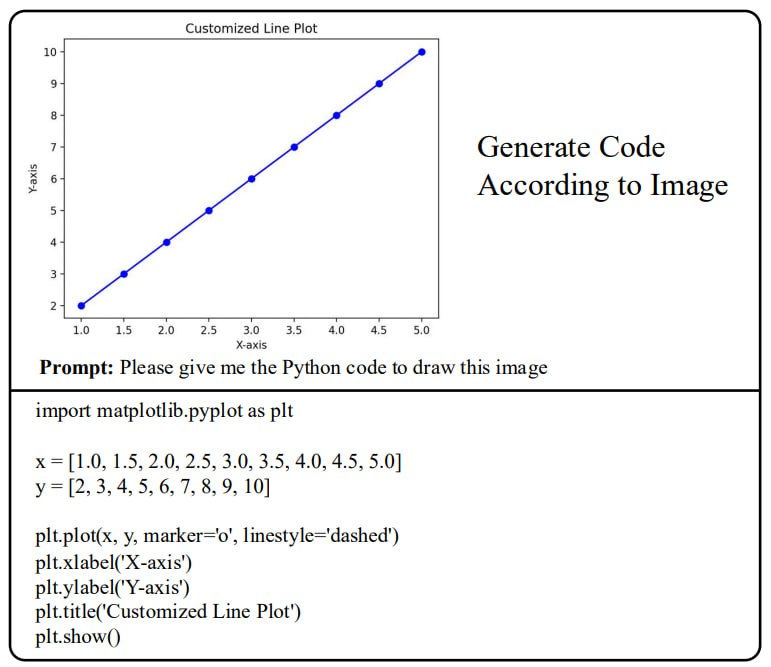
POINTS1.5 была протестирована на бенчмарках MMBench, MMMU, MathVista, HallucinationBench, OCRBench, MMVet, ChartQA, MME, LLaVA-wild, SEEDBench, ScienceQA, MATH-Vision и MathVerse и показала высокие результаты, особенно в задачах, требующих математических навыков.
Модели семейства POINTS могут быть запущены в режиме model soup (совместный запуск нескольких моделей, настроенных с разными наборами инструкций для получения итоговой "усредненной" модели) и CATTY (стратегия разбиения изображения большого разрешения на небольшие фрагменты одинакового размера).
# Clone repo
git clone https://github.com/WePOINTS/WePOINTS.git
# Install required packages
cd WePOINTS
pip install -e .
# Inference example
from transformers import AutoModelForCausalLM, AutoTokenizer
from wepoints.utils.images import Qwen2ImageProcessorForPOINTSV15
import torch
from PIL import Image
import requests
from io import BytesIO
model_path = 'WePOINTS/POINTS-1-5-Qwen-2-5-7B-Chat'
model = AutoModelForCausalLM.from_pretrained(model_path,
trust_remote_code=True,
torch_dtype=torch.float16,
device_map='cuda')
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
image_processor = Qwen2ImageProcessorForPOINTSV15.from_pretrained(model_path)
image_url = '%link to image%'
response = requests.get(image_url)
image_data = BytesIO(response.content)
pil_image = Image.open(image_data)
pil_image = pil_image.save('image.jpg')
prompt = 'please describe the image in detail'
content = [
dict(type='image', image='image.jpg'),
dict(type='text', text=prompt)
]
messages = [
{
'role': 'user',
'content': content
}
]
generation_config = {
'max_new_tokens': 1024,
'temperature': 0.0,
'top_p': 0.0,
'num_beams': 1,
}
response = model.chat(
messages,
tokenizer,
image_processor,
generation_config
)
print(response)
📌Лицензирование: Apache 2.0 License.
▪Модель
▪Arxiv
▪GitHub
▪Руководство по Prompt Engineering
@ai_machinelearning_big_data
#AI #ML #VLM #WePOINTS