tgoop.com/ai_machinelearning_big_data/6185
Last Update:
Marco-o1 – LLM, файнтюн-версия Qwen2-7B-Instruct для решения сложных задач, требующих рассуждений. В создании модели использовались методики Chain-of-Thought (CoT), поиска по дереву Монте-Карло (MCTS) и уникальные стратегии регулирования действий при рассуждении.
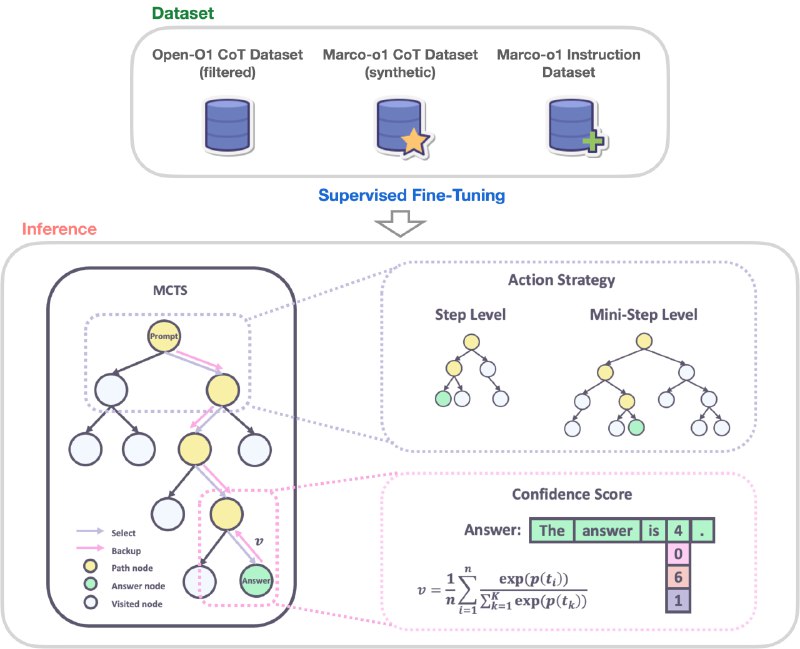
Marco-o1 обучалась на 3 датасетах: отфильтрованный набор данных Open-O1 CoT, синтетический набор Marco-o1 CoT и собственный набор инструкций Marco.
В модели реализованы 2 стратегии действий: "шаг как действие" и "мини-шаг как действие" (32 или 64 токена соответственно). Мини-шаг как действие обеспечивает более детальное исследование пространства решений.
В Marco-o1 был внедрен механизм рефлексии, который побуждает модель переосмысливать свои рассуждения, что улучшает результаты инференса, особенно в сложных составных задачах.
Модель оценивалась на наборах данных MGSM (английский и китайский). Результаты показали, что Marco-o1 превосходит Qwen2-7B-Instruct и демонстрирует улучшение точности на 6,17% для английского набора данных и 5,60% для китайского. Модель превзошла Google Translate в задачах языкового перевода, особенно при переводе разговорных выражений.
В ближайших планах:
# Clone the repository
git clone https://github.com/AIDC-AI/Marco-o1
# Change to the Macaw-LLM directory
cd Marco-o1
# Install required packages
pip install -r requirements.txt
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("AIDC-AI/Marco-o1")
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Marco-o1")
# Run Inference
./src/talk_with_model.py
@ai_machinelearning_big_data
#AI #ML #LLM #CoT #Alibaba #MarcoO1