tgoop.com/ai_machinelearning_big_data/5843
Last Update:
MaskLLM - метод обучения полуструктурированной разреженности для LLM, с которым можно сократить количество используемых параметров без ущерба для качества.
Суть - в моделировании паттернов N:M (где N - количество ненулевых значений в группе из M параметров) в виде обучаемого распределения.
Для дифференцируемой выборки маски используется дискретизация Gumbel Softmax, которая дает возможность проводить сквозное обучение на больших датасетах и получать более точные маски по сравнению с традиционными методами, основанными на эвристических критериях важности параметров.
Главное преимущество MaskLLM - метод может переносить паттерны разреженности между разными задачами и доменами. Это достигается путем обучения общего распределения масок, которое затем можно использовать для настройки на конкретные задачи без необходимости обучения с нуля.
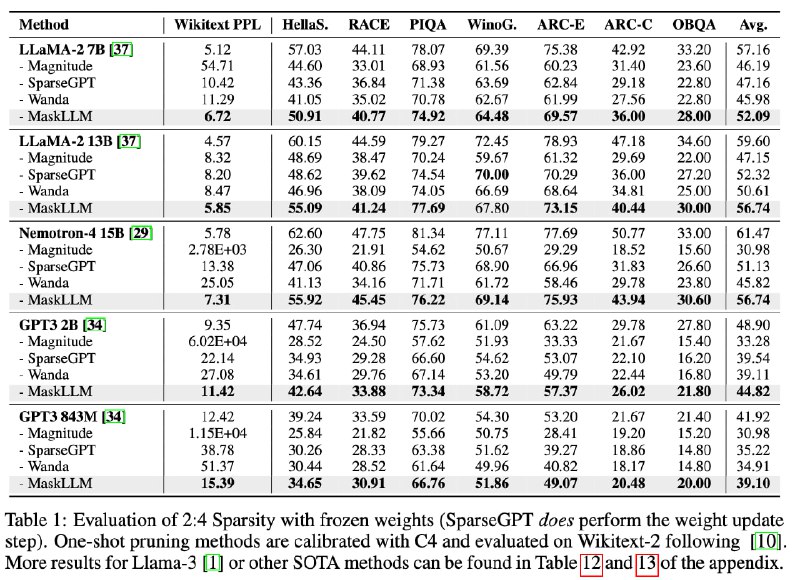
Эффективность MaskLLM оценивали сравнением с другими методами на моделях LLaMA-2, Nemotron-4 и GPT-3.
Результаты показали, что MaskLLM достигает более низкой перплексии на наборе данных Wikitext при использовании 2:4 разреженности. Например, для LLaMA-2 7B MaskLLM достиг перплексии 6.72, в то время как SparseGPT показал результат 10.42.
После этого можно приступать к обрезке целевой модели, и, по завершению, сделать экспорт обученных разреженных моделей в формат Huggingface для дальнейшего использования.
⚠️ Скрипты и инструкции репозитория ориентированы на запуск MaskLLM-LLaMA-2/3 на одном узле с 8 GPU с тензорным параллелизмом и потребует ~40 ГБ на GPU для сквозного обучения.
@ai_machinelearning_big_data
#AI #ML #LLM #MaskLLM