tgoop.com/ai_machinelearning_big_data/5128
Last Update:
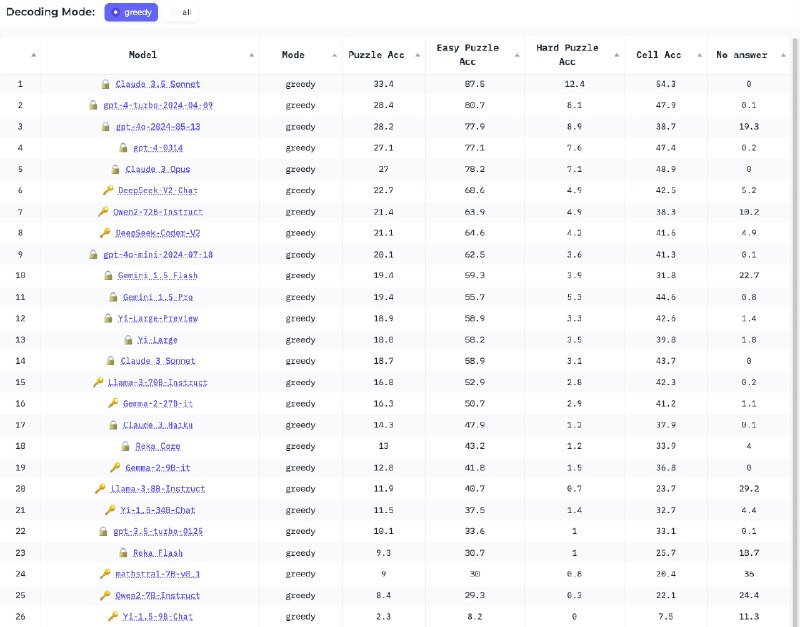
ZebraLogic - бенчмарк, основанный на логических головоломках и представляет собой набор из 1000 программно сгенерированных заданий различной сложности - с сеткой от 2x2 до 6x6.
Каждая головоломка состоит из N домов (пронумерованных слева направо) и M характеристик для каждого дома. Задача заключается в том, чтобы на основе предоставленных подсказок определить уникальное распределение значений характеристик по домам.
Языковым моделям предоставляется один пример решения головоломки с подробным объяснением хода рассуждений и ответом в формате JSON. Затем модели должны решить новую задачу, предоставив как ход рассуждений, так и окончательное решение в заданном формате.
1. Точность на уровне головоломки (процент полностью правильно решенных головоломок).
2. Точность на уровне ячеек (доля правильно заполненных ячеек в матрице решения).
1. Легкие (сетка менее 3x3)
2. Сложные (сетка размером 3x3) и более.
2x2 ~ 15 секунд
3х3 ~ 1 минута 30 секунд
4х4 ~ от 10 до 15 минут
# Install via conda
conda create -n zeroeval python=3.10
conda activate zeroeval
# pip install vllm -U # pip install -e vllm
pip install vllm==0.5.1
pip install -r requirements.txt
# export HF_HOME=/path/to/your/custom/cache_dir/
# Run Meta-Llama-3-8B-Instruct via local, with greedy decoding on `zebra-grid`
bash zero_eval_local.sh -d zebra-grid -m meta-llama/Meta-Llama-3-8B-Instruct -p Meta-Llama-3-8B-Instruct -s 4
@ai_machinelearning_big_data
#AI #Benchmark #LLM #Evaluation #ML