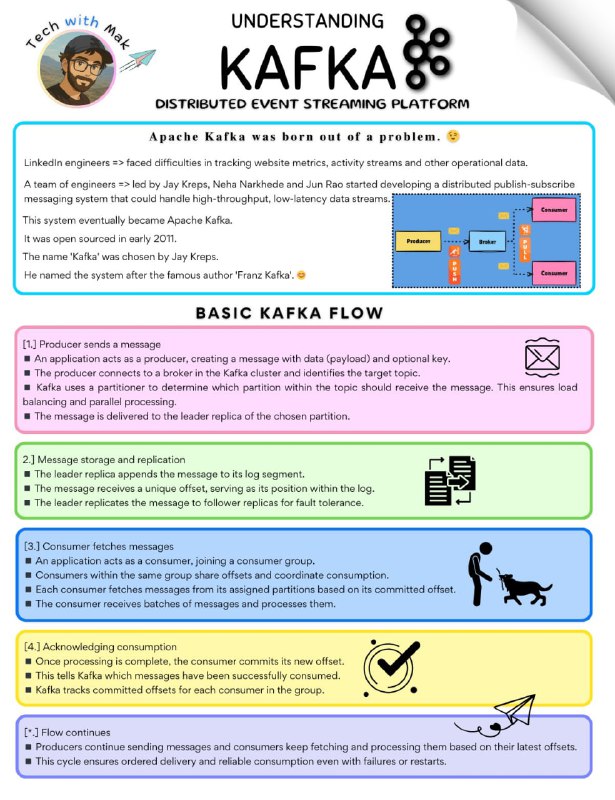
Основной поток Kafka:1. Продюсер отправляет сообщение
⏩Приложение (продюсер) создаёт сообщение с данными.
⏩Продюсер подключается к брокеру Kafka и выбирает тему.
⏩Kafka определяет, в какой раздел темы отправить сообщение, распределяя нагрузку.
⏩Сообщение записывается в лидирующую реплику раздела.
2. Хранение и репликация
⏩Лидер добавляет сообщение в лог и присваивает ему уникальный офсет.
⏩Сообщение копируется на резервные реплики для отказоустойчивости.
3. Консьюмер получает сообщения
⏩Приложение (консьюмер) подключается к группе потребителей.
⏩Консьюмеры координируют обработку, считывая сообщения из своих разделов.
⏩Они получают сообщения партиями, начиная с последнего зафиксированного офсета.
4. Подтверждение обработки
⏩После обработки консьюмер фиксирует новый офсет.
⏩Kafka отслеживает, какие сообщения успешно потреблены.
5. Цикл продолжается
⏩Продюсеры продолжают отправлять, консьюмеры — читать и обрабатывать.
⏩Kafka обеспечивает надёжную и упорядоченную доставку даже при сбоях.
⚠️ Помните:
Поток сообщений в Kafka асинхронный. Продюсеры не ждут, пока консьюмеры обработают сообщения.
Консьюмеры могут отставать от продюсеров, если обработка идёт медленно.
Kafka предлагает механизмы для обработки сбоев и обеспечения семантики доставки at-least-once или exactly-once.
Topics => Partitions => Log Segments
(Данные фактически хранятся в лог-сегментах).
👉 Java Portal