#полезное
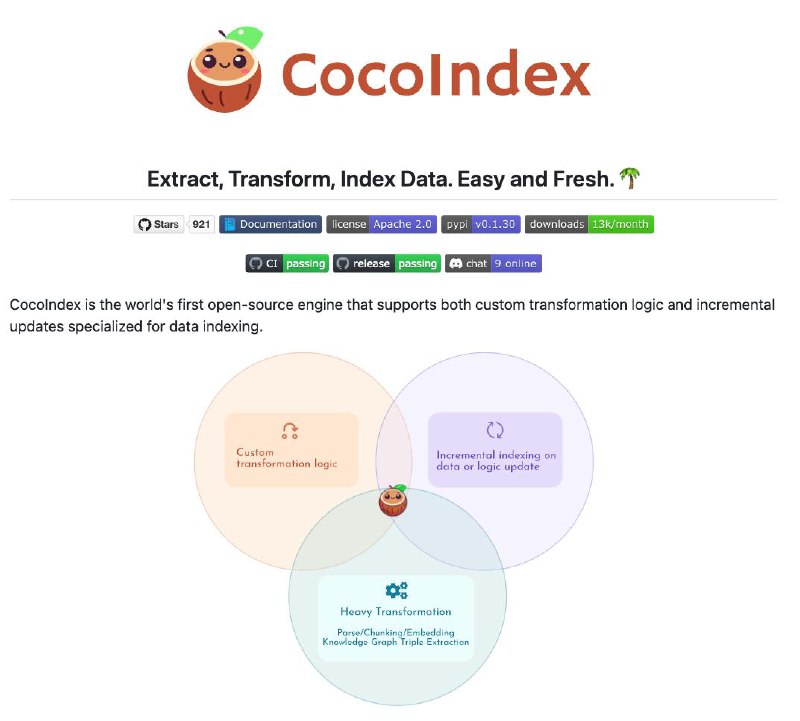
👍 CocoIndex — это современный ETL-фреймворк с открытым исходным кодом, предназначенный для подготовки данных к использованию в системах искусственного интеллекта. Он поддерживает пользовательскую логику трансформации и инкрементальные обновления, что делает его особенно полезным для задач индексации данных.
Основные возможности🟠 Инкрементальная обработка данных: CocoIndex отслеживает изменения в исходных данных и логике трансформации, обновляя только изменённые части индекса, что снижает вычислительные затраты.
🟠 Поддержка пользовательской логики: Фреймворк позволяет интегрировать собственные функции обработки данных, обеспечивая гибкость при построении пайплайнов.
🟠 Модульная архитектура: Встроенные компоненты для чтения данных (локальные файлы, Google Drive), обработки (разбиение на чанки, генерация эмбеддингов) и сохранения результатов (PostgreSQL с pgvector, Qdrant).
🟠 Поддержка различных форматов данных: Поддержка текстовых документов, кода, PDF и структурированных данных, что делает CocoIndex универсальным инструментом.
Примеры использования-
Семантический поиск: Индексация текстовых документов и кода с эмбеддингами для семантического поиска.
-
Извлечение знаний: Построение графов знаний из структурированных данных, извлечённых из документов.
-
Интеграция с LLM: Извлечение структурированной информации из неструктурированных данных с помощью больших языковых моделей.
Быстрый старт
1⃣Установите библиотеку CocoIndex:
pip install -U cocoindex
2⃣Настройте базу данных PostgreSQL с расширением pgvector.
3⃣Создайте файл
quickstart.py и настройте пайплайн обработки данных.
4⃣Запустите пайплайн для обработки и индексации данных.
Гитхаб👉Новости 👉База вопросов