
Дообучение видеомодели Kling на своих данных
Как известно, генерация видео из текста всегда качественнее, чем генерация видео из изображений
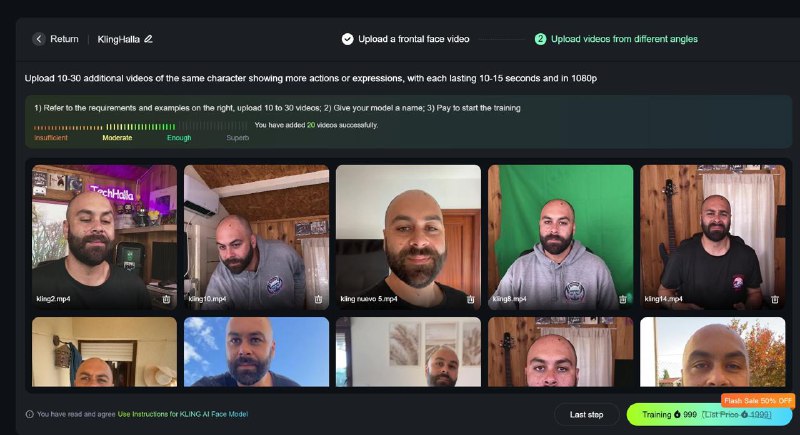
В Kling решили сделать Custom Face Video Model, чтобы можно было загрузить видеоданные с самим собой и обучить собственную видеомодель для полной согласованности персонажа. Это позволит генерировать качественные видео из текста, погружая себя в любые локации и действия. То есть, в результате будет не просто человек с вашим лицом, который ведёт себя, как это предустановлено в модели, а точное повторение ваших жестов и мимики (если они будут в вашем датасете)
Для дообучения модели нужно до 30 горизонтальных видео с собой по 15 секунд, в разных ракурсах. Видео должно быть хорошего качества, с хорошим освещением, без людей на заднем плане. За дообучение берут 999 кредитов (то есть где-то $20)
Далее просто пишем промпт с выбранной моделью лица, описываем, во что одет персонаж и что он делает, а также обстановку, в которой он находится, и т. д.
Думаю, это имеет место быть, особенно если дальше будет возможность совмещать несколько обученных моделей. НО, опять же, при генерации из изображений у нас есть полный контроль над композицией кадра
Обновление скоро появится у всех пользователей
_
А::Й /ВИДЕО — Образовательный проект для нового поколения создателей визуального видео контента. Стартуем 15 ноября. В боте есть скидка @whatisitaivideo_bot
Как известно, генерация видео из текста всегда качественнее, чем генерация видео из изображений
В Kling решили сделать Custom Face Video Model, чтобы можно было загрузить видеоданные с самим собой и обучить собственную видеомодель для полной согласованности персонажа. Это позволит генерировать качественные видео из текста, погружая себя в любые локации и действия. То есть, в результате будет не просто человек с вашим лицом, который ведёт себя, как это предустановлено в модели, а точное повторение ваших жестов и мимики (если они будут в вашем датасете)
Для дообучения модели нужно до 30 горизонтальных видео с собой по 15 секунд, в разных ракурсах. Видео должно быть хорошего качества, с хорошим освещением, без людей на заднем плане. За дообучение берут 999 кредитов (то есть где-то $20)
Далее просто пишем промпт с выбранной моделью лица, описываем, во что одет персонаж и что он делает, а также обстановку, в которой он находится, и т. д.
Думаю, это имеет место быть, особенно если дальше будет возможность совмещать несколько обученных моделей. НО, опять же, при генерации из изображений у нас есть полный контроль над композицией кадра
Обновление скоро появится у всех пользователей
_
А::Й /ВИДЕО — Образовательный проект для нового поколения создателей визуального видео контента. Стартуем 15 ноября. В боте есть скидка @whatisitaivideo_bot
tgoop.com/whatisitsergey/436
Create:
Last Update:
Last Update:
Дообучение видеомодели Kling на своих данных
Как известно, генерация видео из текста всегда качественнее, чем генерация видео из изображений
В Kling решили сделать Custom Face Video Model, чтобы можно было загрузить видеоданные с самим собой и обучить собственную видеомодель для полной согласованности персонажа. Это позволит генерировать качественные видео из текста, погружая себя в любые локации и действия. То есть, в результате будет не просто человек с вашим лицом, который ведёт себя, как это предустановлено в модели, а точное повторение ваших жестов и мимики (если они будут в вашем датасете)
Для дообучения модели нужно до 30 горизонтальных видео с собой по 15 секунд, в разных ракурсах. Видео должно быть хорошего качества, с хорошим освещением, без людей на заднем плане. За дообучение берут 999 кредитов (то есть где-то $20)
Далее просто пишем промпт с выбранной моделью лица, описываем, во что одет персонаж и что он делает, а также обстановку, в которой он находится, и т. д.
Думаю, это имеет место быть, особенно если дальше будет возможность совмещать несколько обученных моделей. НО, опять же, при генерации из изображений у нас есть полный контроль над композицией кадра
Обновление скоро появится у всех пользователей
_
А::Й /ВИДЕО — Образовательный проект для нового поколения создателей визуального видео контента. Стартуем 15 ноября. В боте есть скидка @whatisitaivideo_bot
Как известно, генерация видео из текста всегда качественнее, чем генерация видео из изображений
В Kling решили сделать Custom Face Video Model, чтобы можно было загрузить видеоданные с самим собой и обучить собственную видеомодель для полной согласованности персонажа. Это позволит генерировать качественные видео из текста, погружая себя в любые локации и действия. То есть, в результате будет не просто человек с вашим лицом, который ведёт себя, как это предустановлено в модели, а точное повторение ваших жестов и мимики (если они будут в вашем датасете)
Для дообучения модели нужно до 30 горизонтальных видео с собой по 15 секунд, в разных ракурсах. Видео должно быть хорошего качества, с хорошим освещением, без людей на заднем плане. За дообучение берут 999 кредитов (то есть где-то $20)
Далее просто пишем промпт с выбранной моделью лица, описываем, во что одет персонаж и что он делает, а также обстановку, в которой он находится, и т. д.
Думаю, это имеет место быть, особенно если дальше будет возможность совмещать несколько обученных моделей. НО, опять же, при генерации из изображений у нас есть полный контроль над композицией кадра
Обновление скоро появится у всех пользователей
_
А::Й /ВИДЕО — Образовательный проект для нового поколения создателей визуального видео контента. Стартуем 15 ноября. В боте есть скидка @whatisitaivideo_bot
BY OZEROV
Share with your friend now:
tgoop.com/whatisitsergey/436