
tgoop.com/the_algorithms/4935
Last Update:
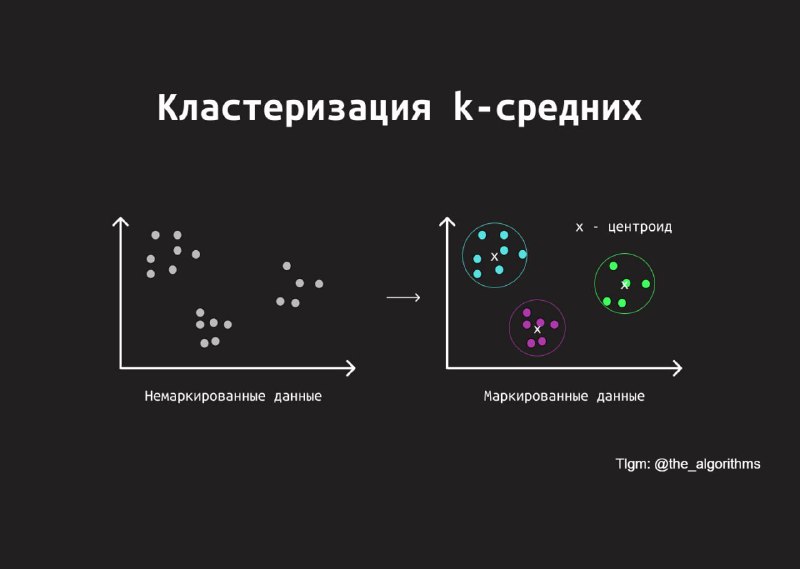
Кластеризация k-средних — Группировка по схожести
Алгоритм k-средних (k-Means) — метод кластеризации без учителя, который делит набор данных на заранее заданное количество кластеров (k). Точки данных группируются вокруг центров кластеров на основе их схожести.
Цель алгоритма — минимизировать сумму квадратов расстояний от каждой точки до ближайшего центра кластера. Проще говоря, он старается сделать кластеры как можно более плотными и четко отделенными друг от друга.
Алгоритм выполняется в несколько шагов:
1) Инициализация центров кластеров: случайным образом выбираются k точек данных в качестве начальных центров.
2) Назначение точек: каждая точка данных привязывается к ближайшему центру на основе расстояния (обычно евклидового).
3) Обновление центров: вычисляются новые центры кластеров как среднее всех точек в каждом кластере.
4) Повтор: процесс назначения и обновления продолжается до тех пор, пока центры не перестанут меняться или не достигнется максимальное количество итераций.
BY Алгоритмы и структуры данных
Share with your friend now:
tgoop.com/the_algorithms/4935