
В Debian есть интересная библиотека libeatmydata, которая подменяет системные вызовы fsync, fdatasync, sync и некоторые другие на пустышки. Эти команды сразу выдают положительный результат, ничего не делая. То есть не работает подтверждение записи на диск.
Это существенно ускоряет все операции записи, но и, что логично, создаёт вероятность потери данных, так как реально они залетают в кэш, а не на диск. И будут записаны в зависимости от настроек и параметров системы, когда ядро посчитает нужным выполнить синхронизацию: по таймеру фоновой синхронизации или недостатка свободной оперативной памяти.
Работает это примерно так:
Реально там ещё пару проверок с if, но по сути всё так и есть для всех системных вызовов, что она она перехватывает.
Эту возможность без особых опасений можно использовать во временных или тестовых средах, где не важна сохранность данных. Причём сделать это очень просто. Ставим пакет:
Запускаем через него любую команду. Я протестировал на старой виртуалке, которую давно не обновляли. Сделал запуск обновления без eatmydata и с ней. Разница получилась заметной.
Напомню, что реальной установкой пакетов занимается утилита
Я выполнил полное обновление пакетов в два этапа, откатив первое обновление на изначальный снепшот:
Работа dpkg занимает где-то треть всего времени, ещё треть загрузка пакетов, и треть пересборка initramfs. Без eatmydata dpkg работала примерно 30 секунд, с ней – 20.
Или вот ещё более наглядный тест. Запускаем создание файла в режиме синхронизации и подтверждения записи каждого блока:
И то же самое через eatmydata:
Эта возможность может пригодиться при сборке контейнеров, образов, раскатки тестовых сред. Можно запускать тестовую СУБД через eatmydata. Да всё, что угодно на тестовом сервере.
Если у вас есть какие-то скрипты, которые не хочется переделывать, добавляя в начало каждой команды eatmydata, можете просто задать переменную окружения, в том числе глобальную в
И все процессы будут писать без подтверждения записи в кэш.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#linux
Это существенно ускоряет все операции записи, но и, что логично, создаёт вероятность потери данных, так как реально они залетают в кэш, а не на диск. И будут записаны в зависимости от настроек и параметров системы, когда ядро посчитает нужным выполнить синхронизацию: по таймеру фоновой синхронизации или недостатка свободной оперативной памяти.
Работает это примерно так:
int fsync(int fd) {
return 0;
}Реально там ещё пару проверок с if, но по сути всё так и есть для всех системных вызовов, что она она перехватывает.
Эту возможность без особых опасений можно использовать во временных или тестовых средах, где не важна сохранность данных. Причём сделать это очень просто. Ставим пакет:
# apt install eatmydataЗапускаем через него любую команду. Я протестировал на старой виртуалке, которую давно не обновляли. Сделал запуск обновления без eatmydata и с ней. Разница получилась заметной.
Напомню, что реальной установкой пакетов занимается утилита
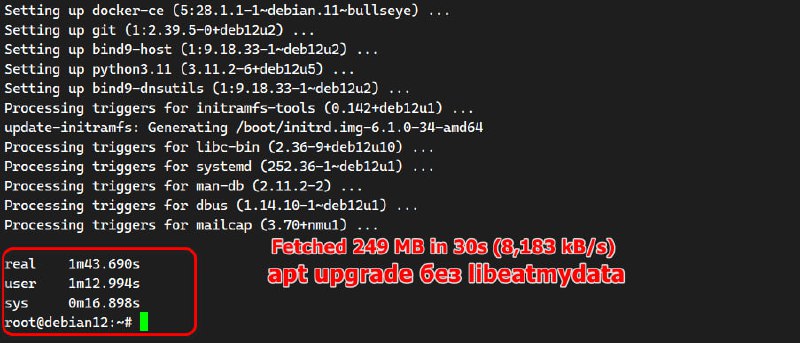
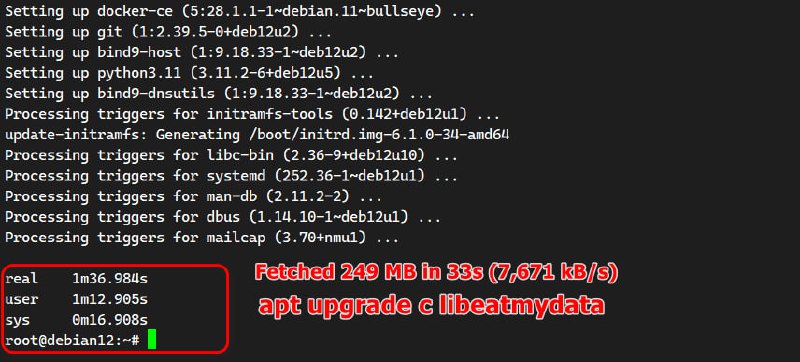
dpkg, а не apt. Dpkg для надёжности выполняет все действия с подтверждением записи. Так что если запустить её через eatmydata, она отработает гораздо быстрее. Я выполнил полное обновление пакетов в два этапа, откатив первое обновление на изначальный снепшот:
# time apt upgrade -yFetched 249 MB in 30s (8,183 kB/s)real 1m 43.690s# time eatmydata apt upgrade -yFetched 249 MB in 33s (7,671 kB/s)real 1m 36.984sРабота dpkg занимает где-то треть всего времени, ещё треть загрузка пакетов, и треть пересборка initramfs. Без eatmydata dpkg работала примерно 30 секунд, с ней – 20.
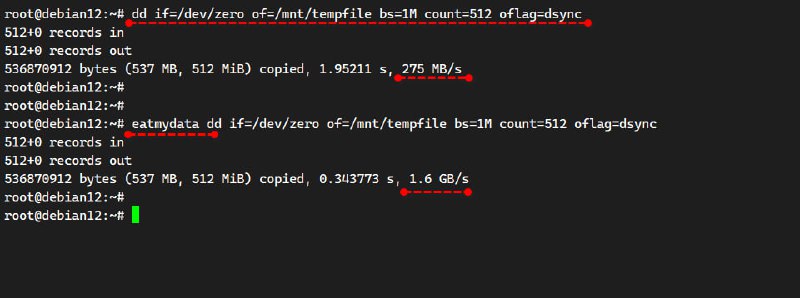
Или вот ещё более наглядный тест. Запускаем создание файла в режиме синхронизации и подтверждения записи каждого блока:
# dd if=/dev/zero of=/mnt/tempfile bs=1M count=512 oflag=dsync536870912 bytes (537 MB, 512 MiB) copied, 1.95211 s, 275 MB/sИ то же самое через eatmydata:
# eatmydata dd if=/dev/zero of=/mnt/tempfile bs=1M count=512 oflag=dsync536870912 bytes (537 MB, 512 MiB) copied, 0.343773 s, 1.6 GB/sЭта возможность может пригодиться при сборке контейнеров, образов, раскатки тестовых сред. Можно запускать тестовую СУБД через eatmydata. Да всё, что угодно на тестовом сервере.
Если у вас есть какие-то скрипты, которые не хочется переделывать, добавляя в начало каждой команды eatmydata, можете просто задать переменную окружения, в том числе глобальную в
/etc/environment:LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libeatmydata.soИ все процессы будут писать без подтверждения записи в кэш.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#linux
tgoop.com/srv_admin/4585
Create:
Last Update:
Last Update:
В Debian есть интересная библиотека libeatmydata, которая подменяет системные вызовы fsync, fdatasync, sync и некоторые другие на пустышки. Эти команды сразу выдают положительный результат, ничего не делая. То есть не работает подтверждение записи на диск.
Это существенно ускоряет все операции записи, но и, что логично, создаёт вероятность потери данных, так как реально они залетают в кэш, а не на диск. И будут записаны в зависимости от настроек и параметров системы, когда ядро посчитает нужным выполнить синхронизацию: по таймеру фоновой синхронизации или недостатка свободной оперативной памяти.
Работает это примерно так:
Реально там ещё пару проверок с if, но по сути всё так и есть для всех системных вызовов, что она она перехватывает.
Эту возможность без особых опасений можно использовать во временных или тестовых средах, где не важна сохранность данных. Причём сделать это очень просто. Ставим пакет:
Запускаем через него любую команду. Я протестировал на старой виртуалке, которую давно не обновляли. Сделал запуск обновления без eatmydata и с ней. Разница получилась заметной.
Напомню, что реальной установкой пакетов занимается утилита
Я выполнил полное обновление пакетов в два этапа, откатив первое обновление на изначальный снепшот:
Работа dpkg занимает где-то треть всего времени, ещё треть загрузка пакетов, и треть пересборка initramfs. Без eatmydata dpkg работала примерно 30 секунд, с ней – 20.
Или вот ещё более наглядный тест. Запускаем создание файла в режиме синхронизации и подтверждения записи каждого блока:
И то же самое через eatmydata:
Эта возможность может пригодиться при сборке контейнеров, образов, раскатки тестовых сред. Можно запускать тестовую СУБД через eatmydata. Да всё, что угодно на тестовом сервере.
Если у вас есть какие-то скрипты, которые не хочется переделывать, добавляя в начало каждой команды eatmydata, можете просто задать переменную окружения, в том числе глобальную в
И все процессы будут писать без подтверждения записи в кэш.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#linux
Это существенно ускоряет все операции записи, но и, что логично, создаёт вероятность потери данных, так как реально они залетают в кэш, а не на диск. И будут записаны в зависимости от настроек и параметров системы, когда ядро посчитает нужным выполнить синхронизацию: по таймеру фоновой синхронизации или недостатка свободной оперативной памяти.
Работает это примерно так:
int fsync(int fd) {
return 0;
}Реально там ещё пару проверок с if, но по сути всё так и есть для всех системных вызовов, что она она перехватывает.
Эту возможность без особых опасений можно использовать во временных или тестовых средах, где не важна сохранность данных. Причём сделать это очень просто. Ставим пакет:
# apt install eatmydataЗапускаем через него любую команду. Я протестировал на старой виртуалке, которую давно не обновляли. Сделал запуск обновления без eatmydata и с ней. Разница получилась заметной.
Напомню, что реальной установкой пакетов занимается утилита
dpkg, а не apt. Dpkg для надёжности выполняет все действия с подтверждением записи. Так что если запустить её через eatmydata, она отработает гораздо быстрее. Я выполнил полное обновление пакетов в два этапа, откатив первое обновление на изначальный снепшот:
# time apt upgrade -yFetched 249 MB in 30s (8,183 kB/s)real 1m 43.690s# time eatmydata apt upgrade -yFetched 249 MB in 33s (7,671 kB/s)real 1m 36.984sРабота dpkg занимает где-то треть всего времени, ещё треть загрузка пакетов, и треть пересборка initramfs. Без eatmydata dpkg работала примерно 30 секунд, с ней – 20.
Или вот ещё более наглядный тест. Запускаем создание файла в режиме синхронизации и подтверждения записи каждого блока:
# dd if=/dev/zero of=/mnt/tempfile bs=1M count=512 oflag=dsync536870912 bytes (537 MB, 512 MiB) copied, 1.95211 s, 275 MB/sИ то же самое через eatmydata:
# eatmydata dd if=/dev/zero of=/mnt/tempfile bs=1M count=512 oflag=dsync536870912 bytes (537 MB, 512 MiB) copied, 0.343773 s, 1.6 GB/sЭта возможность может пригодиться при сборке контейнеров, образов, раскатки тестовых сред. Можно запускать тестовую СУБД через eatmydata. Да всё, что угодно на тестовом сервере.
Если у вас есть какие-то скрипты, которые не хочется переделывать, добавляя в начало каждой команды eatmydata, можете просто задать переменную окружения, в том числе глобальную в
/etc/environment:LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libeatmydata.soИ все процессы будут писать без подтверждения записи в кэш.
❗️Если заметка вам полезна, не забудьте 👍 и забрать в закладки.
#linux
BY ServerAdmin.ru
Share with your friend now:
tgoop.com/srv_admin/4585