
tgoop.com/quant_prune_distill/425
Create:
Last Update:
Last Update:
Matryoshka Quantization
[Статья]
[Код есть, но мы вам его не покажем]
Введение
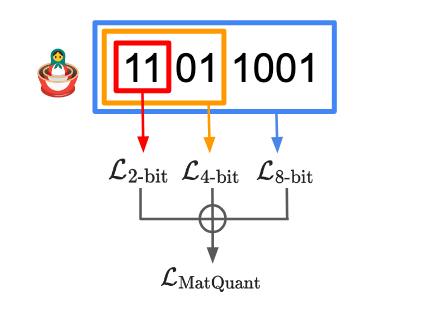
Большинство методов квантизации готовят модель в некоторой заданной битности, и, если хочется иметь квантизованные модели разной степени сжатия, приходится прогонять алгоритм несколько раз и хранить где—то всю полученную пачку.
Команда из Глубокого Разума 🧠 на днях выкатила статейку по квантизации с примечательным названием Matryoshka Quantization 🪆, которая за один присест готовит квантизованные модельки в 2,4 и 8 бит.
Примечательно, что один из авторов, Kusupati, ранее публиковал другую работу про матрешки — Matryoshka Representation Learning.
BY КПД
Share with your friend now:
tgoop.com/quant_prune_distill/425