
tgoop.com/quant_prune_distill/421
Last Update:
QuEST: Stable Training of LLMs with 1-Bit Weights and Activations
[Статья][Код]
Введение
Уважаемые коллеги из IST, в частности, @black_samorez_channel выпустили статью про стабильное обучение моделей с квантизованными весами и активациями.
Статей с той же аббревиатурой пруд пруди на архиве:
- Вот
- Вот
- Вот
- И вот
Но эта - особенная!
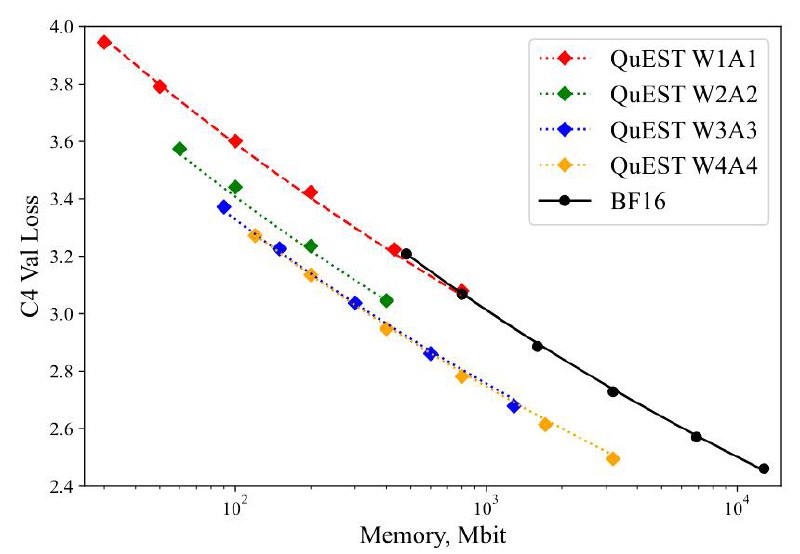
Ранее уже неоднократно поднимался (в том числе и на этом канале) вопрос о том, в какой точности оптимально учить модель (веса и активации), дабы получить наилучшее качество при заданном размере (через PTQ или QAT). Ранее утверждали, что 6-7 бит оптимально при квантизации весов и активаций в INTx/FPx. Но сама процедура была незамысловата, и нет гарантий, что нельзя пробить существенно Парето-фронт. Свежие результаты (смотри краткий обзор на gonzo-ml) показывают, что в fp4 тоже можно эффективно обучать.
В данной же статье авторам удается достичь Парето-оптимальности в W3A3/W4A4 и стабильного обучения в W1A1 😮 (уже не оптимального, но на одном уровне с fp16).
BY КПД
Share with your friend now:
tgoop.com/quant_prune_distill/421