
tgoop.com/quant_prune_distill/418
Last Update:
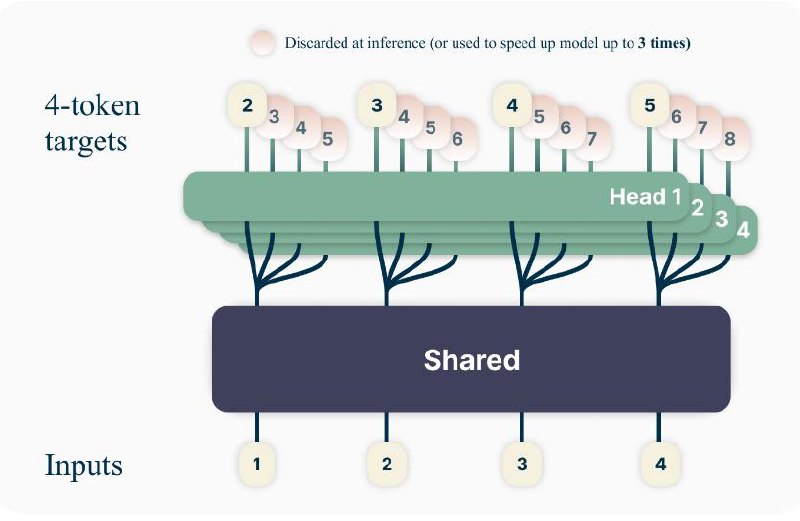
Better & Faster Large Language Models via Multi-token Prediction
[Статья] [Кода нет, но есть модели]
Введение
Раз уж пост вышел на Love. Death. Transformers. и братва требует пояснений, разберем.
За последние несколько лет мы наблюдали несколько качественных скачков возможностей LLM. Однако в основе их работы все еще (преимущественно) лежит задача предсказания следующего токена.
Данная незамысловатая задача позволяет решать задачи любой сложности, но существенным недостатком является дороговизна 💵 инференса, когда ради одного несчастного токена приходится загружать всю модель (или часть слоев в случае MoE) в быструю память и сгружать обратно.
Дабы повысить эффективность инференса предлагается незамысловатое решение - предсказывать несколько токенов за раз. На самом деле такое уже было еще в далеком 2020-м году, и в сценарии дообучения однотокенной модели (Medusa). Заслуга авторов из Меты в том, что они исследовали разные варианты предсказания токенов для моделей разного размера.
BY КПД
Share with your friend now:
tgoop.com/quant_prune_distill/418