tgoop.com/pytorch_howsam/613
Create:
Last Update:
Last Update:
سباستین راشکا یک وبلاگ درباره مقالات تحقیقاتی برجسته در سال 2024 نوشته. اولش گفته که انقدر حجم کارهای تحقیقاتی ارزشمند سال 2024 زیاد هست که باید کتاب نوشت! به همین خاطر، تصمیم گرفته، هر ماه از سال 2024 رو به یک کار ارزشمند اختصاص بده. فعلا، شش ماه اول سال 2024 رو نوشته. اگه خواستید، میتونید از لینک زیر مطالعه کنید.
Noteworthy AI Research Papers of 2024 (Part One)
ماه قبل، راشکا گفت که تصادف کرده و آسیب دیده. یک مدتی نمیتونست پشت میز بشینه و کار کنه. توی این پست گفت که حالش بهتره. امیدوارم به خوبی ریکاوری کنه.
من هم تصمیم گرفتم که کار مربوط به هر ماه رو بهصورت خلاصه اینجا بنویسم. توی این پست درباره کار ماه ژانویه نوشتم.
1. ژانویه: روش Mixture of Experts مدل Mixtral
تنها چند روز پس از شروع ژانویه 2024، تیم Mistral AI مقاله Mixtral of Experts یا MoE را (در تاریخ 8 ژانویه 2024) منتشر کرد. آنها در این مقاله، مدل Mixtral 8x7B را معرفی کردند.
این مقاله و مدل در زمان خود بسیار تاثیرگذار بود، چون Mixtral 8x7B یکی از اولین مدلهای MoE با وزنهای باز (open-weight) بود که عملکرد چشمگیری داشت و در معیارهای مختلف، Llama 2 70B و GPT-3.5 را پشت سر گذاشته بود.
مدل MoE یا Mixture of Experts چیست؟
یک مدل تجمعی که چندین زیرشبکه کوچک "متخصص" (Expert) را در یک معماری شبیه به GPT ترکیب میکند. میتوان گفت، هر زیرشبکه مسئول انجام یکسری تسک خاص و متفاوت هست. استفاده از چندین زیرشبکه کوچک به جای یک شبکه بزرگ باعث میشود که مدلهای MoE منابع محاسباتی را به صورت بهینهتری استفاده کنند.
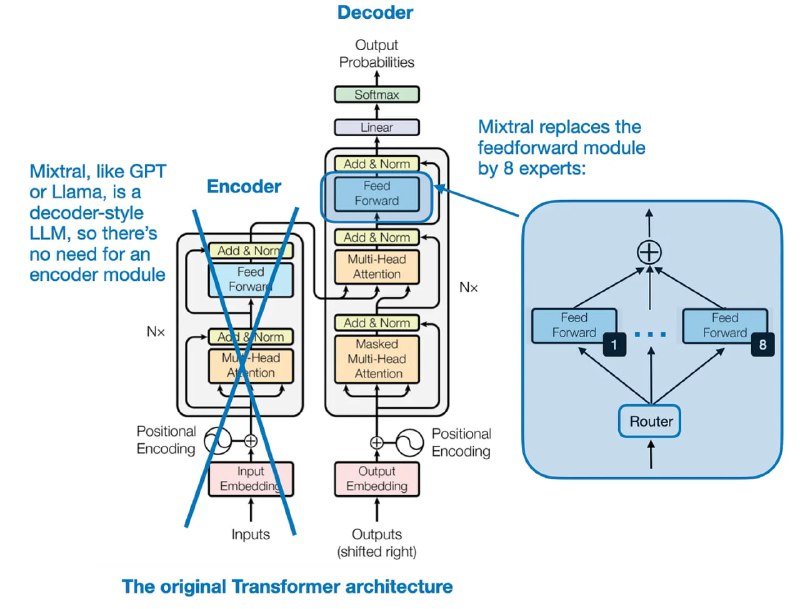
ساختار مدل Mixtral 8x7B به چه شکلی هست؟
در شکل بالا ساختار مدل Mixtral 8x7B نشان داده شده است. بهطور خاص، در Mixtral 8x7B، هر ماژول Feed-Forward در معماری ترنسفورمر با 8 لایه متخصص (Expert) جایگزین شده است.
در شکل چهار نکته مهم وجود دارد:
1) معماری مدل شبیه به GPT (مبتنی بر دیکدر) هست.
2) 8 متخصص در ماژول فیدفورارد قرار گرفتهاند.
3) یک ماژول Router وجود دارد که توکنها را به 8 ماژول متخصص فیدفورارد هدایت میکند.
4) خروجی این 8 ماژول متخصص با یکدیگر جمع میشوند.
@pytorch_howsam