
tgoop.com/pythonwithmedev/343
Last Update:
تحلیل دیتاستهای جدولی (Tabular) هم در ریسرچ و هم در کاربردهای واقعی خیلی مورد توجه هست. مقایسههایی که تا الان انجام شده، نشون میده عملکرد مدلهای دیپ اغلب پایینتر یا همسطح مدلهای بوستینگ گرادیان (GBMs) هست.
میخوام درباره مقالهای صحبت کنم که مقایسه عمیقی روی مدلهای آنسامبل مبتنی بر درخت تصمیم (TE)، دیپ (DL) و مدلهای کلاسیک ML انجام داده. عنوان مقاله:
A Comprehensive Benchmark of Machine and Deep Learning Across Diverse Tabular Datasets link
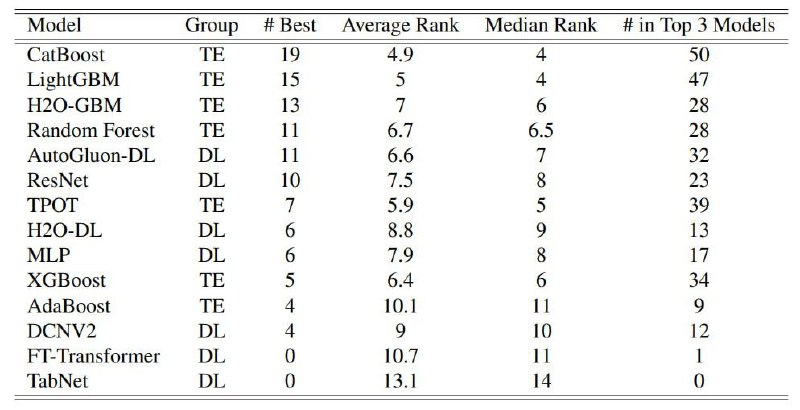
حدود 111 دیتاست جدولی و 20 مدل مختلف برای مقایسه انتخاب شده. مقایسههای متنوعی انجام شده؛ مقایسه عملکرد مدلهای DL و TE رو در تصویر بالا آوردم. نتایج جالبی بدست اومده:
* مدل CatBoost در 19 مورد از 111 دیتاست بهترین بوده.
* رتبه Random Forest قابل توجه هست.
* مدل XGBoost که خیلیها انتخاب اولشون هست، در رتبه 10 دیده میشه!
* رتبه اول تا چهارم رو مدلهای ML اشغال کردن.
* اولین مدل دیپ لرنینگی در رتبه 5 دیده میشه.
* شبکه MLP در رتبه 9 دیده میشه.
* شبکه TabNet آخره!
مقاله بخشهای متنوعی داره و من فقط یک مقایسه رو آوردم. شاید بعدا بیشتر بنویسم.
BY 🧑💻Cyber.vision🧑💻
Share with your friend now:
tgoop.com/pythonwithmedev/343