
tgoop.com/pythonlearnme/270
Last Update:
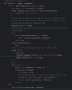
1. if self._state.adding and not self.slug:
- قسمت اول چک کردن یعنی self._state.adding اگر در حال ساختن یک شی جدید در دیتابیس باشیم مساوی با True هستش همچنین اسلاگ هم باید None باشه.
2. self.slug = self.slugify(self.name)
- این خط یک slug جدید را بر اساس فیلد name با استفاده از تابع slugify تولید میکند.
3. using = kwargs.get("using" or router.db_for_write(type(self), instance=self))
- این خط مشخص میکند که دادهها باید در کدام پایگاه داده ذخیره شوند، با استفاده از router.db_for_write.
(درباره B router بعدا توضیح میدم)
4. kwargs["using"] = using
- این خط، پارامتر using را در kwargs قرار میدهد تا در ادامه به super().save منتقل شود.
5. try: ... except IntegrityError:
- این بلوک try/except یک تراکنش atomic را برای ذخیره دادهها ایجاد میکند.
- اگر خطای IntegrityError (مانند تکراری بودن slug) رخ دهد، بلوک except اجرا میشود.
6. slugs = set(...)
- در صورت رخ دادن `IntegrityError`، این خط تمام `slug`های موجود در پایگاه داده که اولشون شبیه به اسلاگ ما هستش رو بازیابی می کنه.
7. while True: ... i += 1
- این حلقه یک slug جدید تولید میکند تا زمانی که یک slug منحصر به فرد پیدا شود.- slug جدید با افزودن یک شماره انتهایی به slug قبلی تولید میشود (مانند my-slug-1, my-slug-2, و غیره).
8. return super().save(*args, **kwargs)
- بعد از یافتن یک slug منحصر به فرد، شیء با فراخوانی متد save پایه ذخیره میشود.
9. else: return super().save(*args, **kwargs)
- اگر شیء در حال بهروزرسانی است (نه ایجاد)، متد save پایه بدون هیچ تغییری فراخوانی میشود.
این کد به این دلیل طراحی شده است تا یک slug منحصر به فرد برای هر شی ایجاد کند، حتی اگر نامهای مشابهی در پایگاه داده وجود داشته باشد. همچنین از تراکنشهای اتمیک برای حفظ یکپارچگی دادهها در طول عملیات ذخیرهسازی استفاده میکند.
BY 🧑💻PythonDev🧑💻
Share with your friend now:
tgoop.com/pythonlearnme/270