
👍 Эффективная работа с JSON Lines в Python: сравнение библиотек
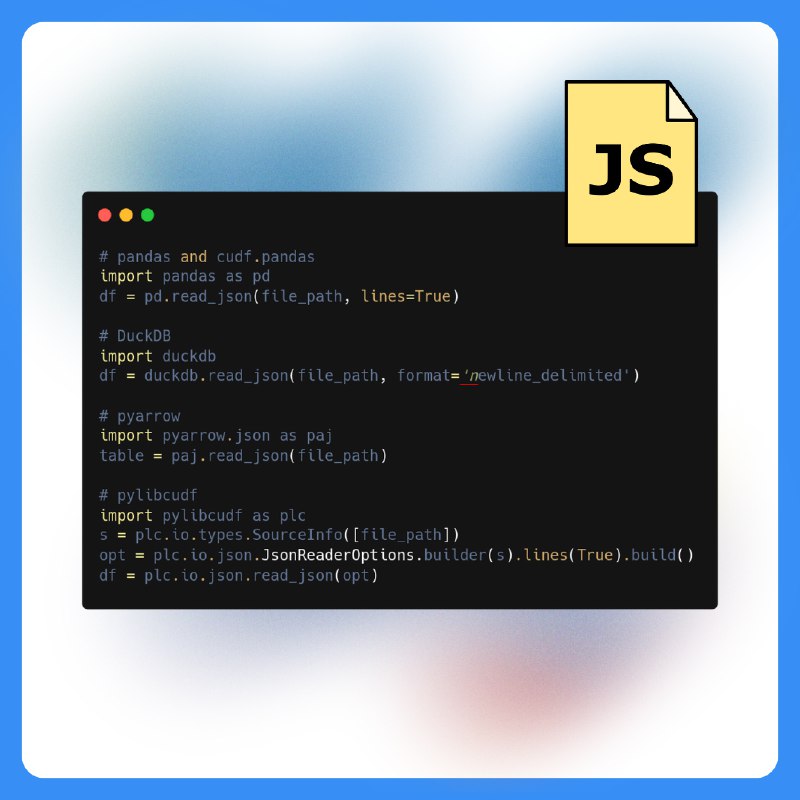
JSON — популярный формат для обмена данными, но его обработка в data science и data engineering может быть сложной. Часто данные представлены в виде JSON Lines (NDJSON), и первый шаг — преобразование их в dataframe.
В статье от Nvidia сравнивают производительность и функциональность Python-библиотек:
✅ pandas
✅ DuckDB
✅ pyarrow
✅ RAPIDS cuDF pandas Accelerator Mode
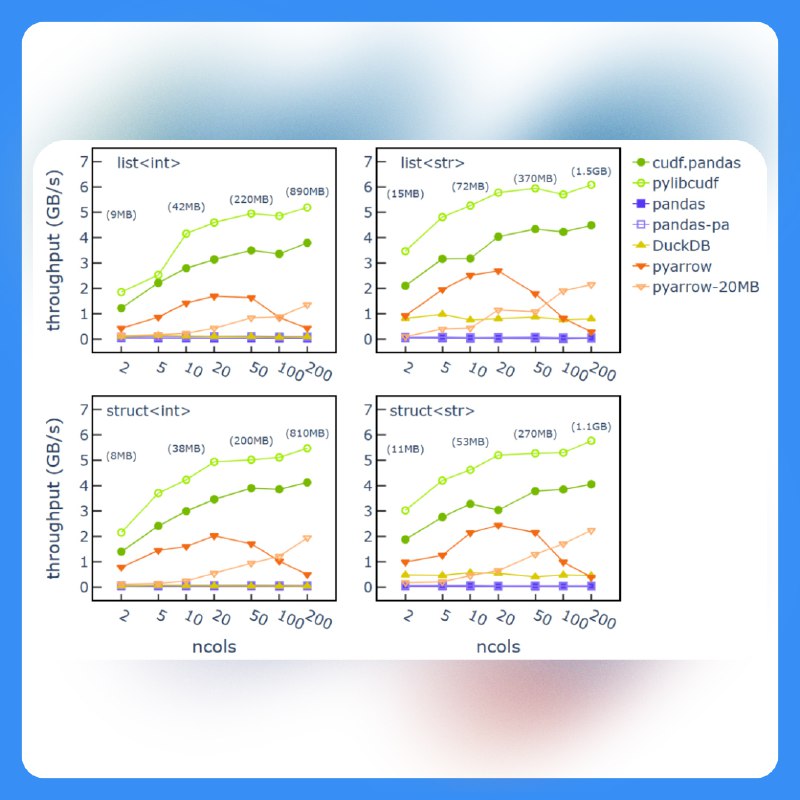
Результаты:
📊 cuDF.pandas показывает отличное масштабирование и высокую пропускную способность, особенно для сложных данных.
🔧 Широкий набор опций JSON-ридера в cuDF повышает совместимость с Apache Spark и упрощает обработку аномалий в JSON.
Статья: https://clc.to/m8Lsog
JSON — популярный формат для обмена данными, но его обработка в data science и data engineering может быть сложной. Часто данные представлены в виде JSON Lines (NDJSON), и первый шаг — преобразование их в dataframe.
В статье от Nvidia сравнивают производительность и функциональность Python-библиотек:
✅ pandas
✅ DuckDB
✅ pyarrow
✅ RAPIDS cuDF pandas Accelerator Mode
Результаты:
📊 cuDF.pandas показывает отличное масштабирование и высокую пропускную способность, особенно для сложных данных.
🔧 Широкий набор опций JSON-ридера в cuDF повышает совместимость с Apache Spark и упрощает обработку аномалий в JSON.
Статья: https://clc.to/m8Lsog
👍12❤3🔥1
tgoop.com/pyproglib/6463
Create:
Last Update:
Last Update:
👍 Эффективная работа с JSON Lines в Python: сравнение библиотек
JSON — популярный формат для обмена данными, но его обработка в data science и data engineering может быть сложной. Часто данные представлены в виде JSON Lines (NDJSON), и первый шаг — преобразование их в dataframe.
В статье от Nvidia сравнивают производительность и функциональность Python-библиотек:
✅ pandas
✅ DuckDB
✅ pyarrow
✅ RAPIDS cuDF pandas Accelerator Mode
Результаты:
📊 cuDF.pandas показывает отличное масштабирование и высокую пропускную способность, особенно для сложных данных.
🔧 Широкий набор опций JSON-ридера в cuDF повышает совместимость с Apache Spark и упрощает обработку аномалий в JSON.
Статья: https://clc.to/m8Lsog
JSON — популярный формат для обмена данными, но его обработка в data science и data engineering может быть сложной. Часто данные представлены в виде JSON Lines (NDJSON), и первый шаг — преобразование их в dataframe.
В статье от Nvidia сравнивают производительность и функциональность Python-библиотек:
✅ pandas
✅ DuckDB
✅ pyarrow
✅ RAPIDS cuDF pandas Accelerator Mode
Результаты:
📊 cuDF.pandas показывает отличное масштабирование и высокую пропускную способность, особенно для сложных данных.
🔧 Широкий набор опций JSON-ридера в cuDF повышает совместимость с Apache Spark и упрощает обработку аномалий в JSON.
Статья: https://clc.to/m8Lsog
BY Библиотека питониста | Python, Django, Flask
Share with your friend now:
tgoop.com/pyproglib/6463