
tgoop.com/pro_nocode/429
Create:
Last Update:
Last Update:
Небольшой хак про то, как ускорить проверку результатов поиска при помощи LLM в n8n
Ситуация: у вас есть запрос пользователя и векторный поиск из которого вы достаёте результаты запроса. Но не все результаты подходят под запрос.
Чтобы удобнее работать с результатами привожу их в формат json. Примерно вот так:
{
"articles": [
{
"name": "Статья 1",
"description": "Автоматизация процессов с гибкими настройками.",
"url": "https://example.com/art1"
},
{
"name": "Статья 2",
"description": "Анализ данных для принятия решений.",
"url": "https://example.com/art2"
},
{
"name": "Статья 3",
"description": "Упрощение коммуникации и автоматизация задач.",
"url": "https://example.com/art3"
}
]
}
Задача: провалидировать результаты запроса с самим запросом и вернуть только то, что актуально и релевантно для пользователя.
Решение:
Использую open ai как финальный шаг по валидации результатов.
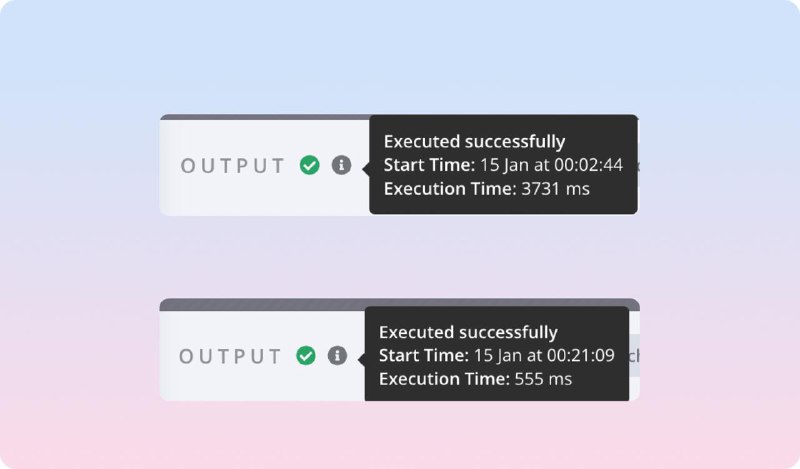
Изначально я просил LLM проанализировать запрос с полученными результатами и вернуть то, что релевантно. В таком случае я и на вход передавал JSON и на выходе получал JSON и это отрабатывало долго. 3-4 секунды в среднем.
Решил пойти другим путём и просить LLM вернуть только индексы результатов, которые подходят под запрос. А уже следующим шагом уже кодом достаю нужные результаты и возвращаю их пользователю.
Получился своеобразный костыль-валидатор, но это заметно улучшило качество выдачи и скорость проверки. Использую mini модель.
Пример промпта для валидации:
You have a user request and a list of articles that can help them solve their request. Your task is to select the most relevant articles and return their index. Use key "indexes". Indexes should start from 0. Rank the indexes by relevance in descending order.
User request:
{{ выражение для n8n }}
Articles:
{{ выражение для n8n }}
В результате получил и более быструю проверку(прикрепил к посту) на релевантность и сокращение количества токенов для проверки.
BY Канал про NoCode
Share with your friend now:
tgoop.com/pro_nocode/429