
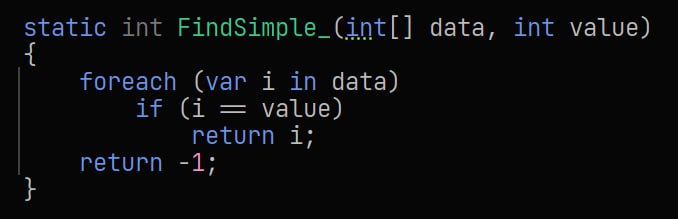
Продолжаем ковырять SSE/AVX, но тут кажется мне не помешала бы пояснительная бригада. Для поиска элемента в
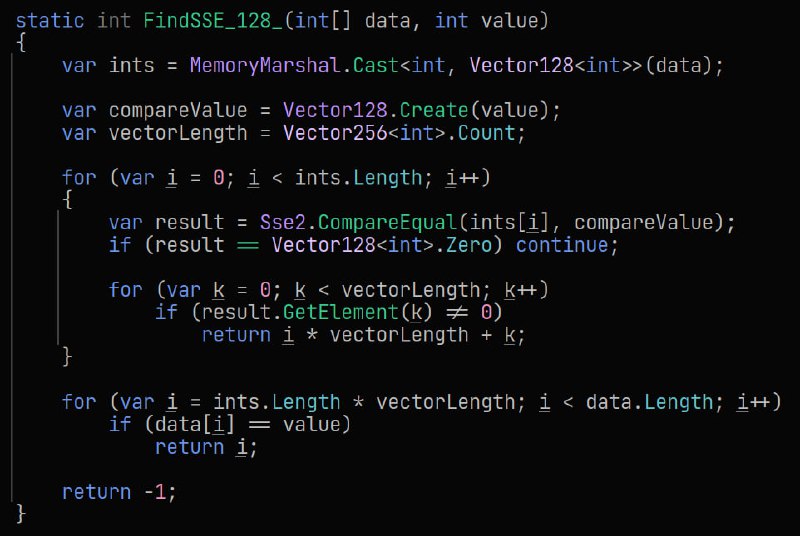
До 2048 (8 КБ данных) всё работает более менее - х1.5-2 для Vector128 и ещё больше для Vector256. Однако дальше Vector128 проседает по скорости до обычного цикла на 2048 элементов (8 КБ данных) и становится медленее, чем простой цикл для 4096+ (32 КБ данных) элементов.
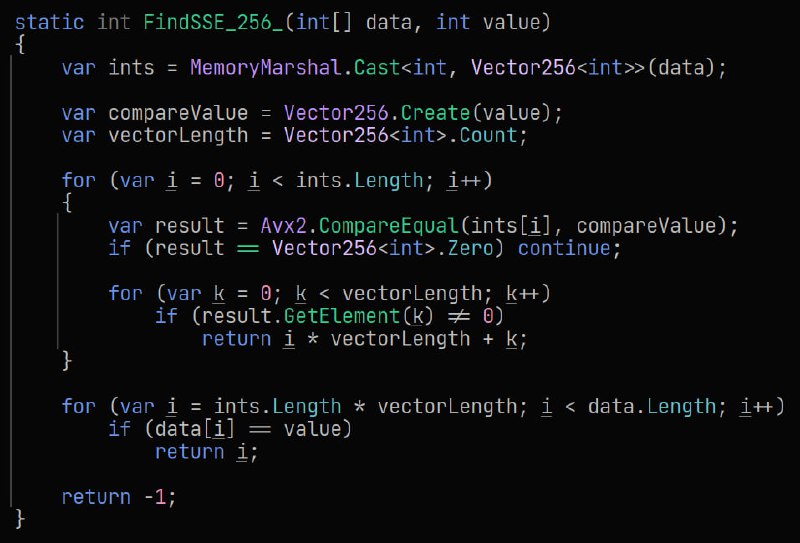
Vector256 проседает попозже - начиная с 5120 (20 КБ данных) элементов он сравнивается со скоростью простого цикла.
Vector128 становится медленее всех, начиная с 3072 (12 КБ данных) элементов
Пока что у меня два объяснения:
🔸 влияние L2 кэша, он насыщается и за счёт того, что данные берутся из RAM скорость резко падает
🔸 процессор уходит в throttling, однако неясно почему Vector128 становица хуже чем простой цикл (хотя возможно JIT делает loop unroll и за счёт этого получается обычный цикл быстрее)
Второй вариант я попробовал исключить, переключив режим проца в Turbo (специальной утилитой Asus), скорости чуть-чуть подросли (буквально на 4-5%), но тренды не поменялись.
С ushort ситуация выглядит другим образом - самым быстрым практически везде является
gist_int gist_ushort #sse #simd #dotnet
int[] используется Sse2.CompareEqual, которая может сравнивать 4 (Vector128) или 8 (Vector256) элементов.До 2048 (8 КБ данных) всё работает более менее - х1.5-2 для Vector128 и ещё больше для Vector256. Однако дальше Vector128 проседает по скорости до обычного цикла на 2048 элементов (8 КБ данных) и становится медленее, чем простой цикл для 4096+ (32 КБ данных) элементов.
Vector256 проседает попозже - начиная с 5120 (20 КБ данных) элементов он сравнивается со скоростью простого цикла.
Vector128 становится медленее всех, начиная с 3072 (12 КБ данных) элементов
Пока что у меня два объяснения:
🔸 влияние L2 кэша, он насыщается и за счёт того, что данные берутся из RAM скорость резко падает
🔸 процессор уходит в throttling, однако неясно почему Vector128 становица хуже чем простой цикл (хотя возможно JIT делает loop unroll и за счёт этого получается обычный цикл быстрее)
Второй вариант я попробовал исключить, переключив режим проца в Turbo (специальной утилитой Asus), скорости чуть-чуть подросли (буквально на 4-5%), но тренды не поменялись.
С ushort ситуация выглядит другим образом - самым быстрым практически везде является
Vector128<ushort> 😳 однако разрыв по скорости в разы - только <=2048 элементов (4 КБ данных), дальше разрыв крайне незначительный.gist_int gist_ushort #sse #simd #dotnet
tgoop.com/notes_of_programmer/232
Create:
Last Update:
Last Update:
Продолжаем ковырять SSE/AVX, но тут кажется мне не помешала бы пояснительная бригада. Для поиска элемента в
До 2048 (8 КБ данных) всё работает более менее - х1.5-2 для Vector128 и ещё больше для Vector256. Однако дальше Vector128 проседает по скорости до обычного цикла на 2048 элементов (8 КБ данных) и становится медленее, чем простой цикл для 4096+ (32 КБ данных) элементов.
Vector256 проседает попозже - начиная с 5120 (20 КБ данных) элементов он сравнивается со скоростью простого цикла.
Vector128 становится медленее всех, начиная с 3072 (12 КБ данных) элементов
Пока что у меня два объяснения:
🔸 влияние L2 кэша, он насыщается и за счёт того, что данные берутся из RAM скорость резко падает
🔸 процессор уходит в throttling, однако неясно почему Vector128 становица хуже чем простой цикл (хотя возможно JIT делает loop unroll и за счёт этого получается обычный цикл быстрее)
Второй вариант я попробовал исключить, переключив режим проца в Turbo (специальной утилитой Asus), скорости чуть-чуть подросли (буквально на 4-5%), но тренды не поменялись.
С ushort ситуация выглядит другим образом - самым быстрым практически везде является
gist_int gist_ushort #sse #simd #dotnet
int[] используется Sse2.CompareEqual, которая может сравнивать 4 (Vector128) или 8 (Vector256) элементов.До 2048 (8 КБ данных) всё работает более менее - х1.5-2 для Vector128 и ещё больше для Vector256. Однако дальше Vector128 проседает по скорости до обычного цикла на 2048 элементов (8 КБ данных) и становится медленее, чем простой цикл для 4096+ (32 КБ данных) элементов.
Vector256 проседает попозже - начиная с 5120 (20 КБ данных) элементов он сравнивается со скоростью простого цикла.
Vector128 становится медленее всех, начиная с 3072 (12 КБ данных) элементов
Пока что у меня два объяснения:
🔸 влияние L2 кэша, он насыщается и за счёт того, что данные берутся из RAM скорость резко падает
🔸 процессор уходит в throttling, однако неясно почему Vector128 становица хуже чем простой цикл (хотя возможно JIT делает loop unroll и за счёт этого получается обычный цикл быстрее)
Второй вариант я попробовал исключить, переключив режим проца в Turbo (специальной утилитой Asus), скорости чуть-чуть подросли (буквально на 4-5%), но тренды не поменялись.
С ushort ситуация выглядит другим образом - самым быстрым практически везде является
Vector128<ushort> 😳 однако разрыв по скорости в разы - только <=2048 элементов (4 КБ данных), дальше разрыв крайне незначительный.gist_int gist_ushort #sse #simd #dotnet
BY 📓 Записки программера

Share with your friend now:
tgoop.com/notes_of_programmer/232