
{kind=link}
Мощные небольшие модели с помощью дистилляции
Дистилляция моделей — это путь от прототипа к масштабированию. При использовании крупных моделей, таких как GPT-4o, разработчики сталкиваются с проблемами: время отклика, лимиты на запросы и высокая стоимость. Например, GPT-4o набирает 88% на MMLU, а его уменьшенная версия GPT-4o Mini — 82%. Но важен ли этот показатель для реальных задач?
Дистилляция: узкий фокус вместо широкого интеллекта
Большие модели часто превосходят по академическим метрикам, но такие тесты не всегда отражают реальные потребности пользователей. Здесь на сцену выходит дистилляция: не нужн широкий интеллект, а только узкий. Мы обучаем меньшую модель на основе данных, сгенерированных большой моделью.
Как это работает:
1 Оценка задач: Определение критериев, по которым модель будет оцениваться.
2 Сбор данных: Запись качественных ответов большой модели.
3 Файнтюнинг: Обучение маленькой модели на этих данных.
Основные сложности
На практике только около 15% разработчиков используют API для файнтюнинга. Главная сложность — создание качественного набора данных для обучения. Однако OpenAI представила два новых инструмента, которые упрощают этот процесс:
1 Stored Completions: Сохранение ответов моделей с параметром store=True.
2 Evals (beta): Оценка производительности модели прямо в интерфейсе Playground.
Теперь вы можете сохранять все выходные данные большой модели и добавлять метаданные, такие как разделение на тест и обучение. Во вкладке Evals можно настроить критерии оценки и сразу видеть результаты. Этот новый инструмент значительно упрощает процесс.
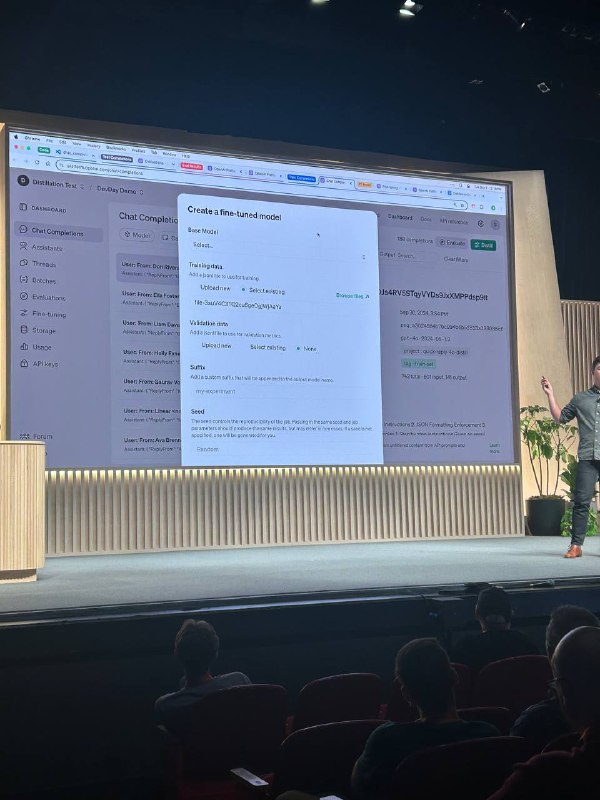
Дистилляция GPT-4o в GPT-4o-mini
Процесс дистилляции прост:
• Определите критерии оценки
• Сохраните результаты большой модели
• Нажмите "Distill" и выберите GPT-4o-mini в качестве базовой модели.
Через некоторое время вы получите настроенную модель, которая работает немного хуже GPT-4o, но значительно легче и дешевле в использовании.
Примеры и рекомендации
Где дистилляция наиболее эффективна:
• Анализ тональности
• Извлечение сущностей
• Майндинг мнений
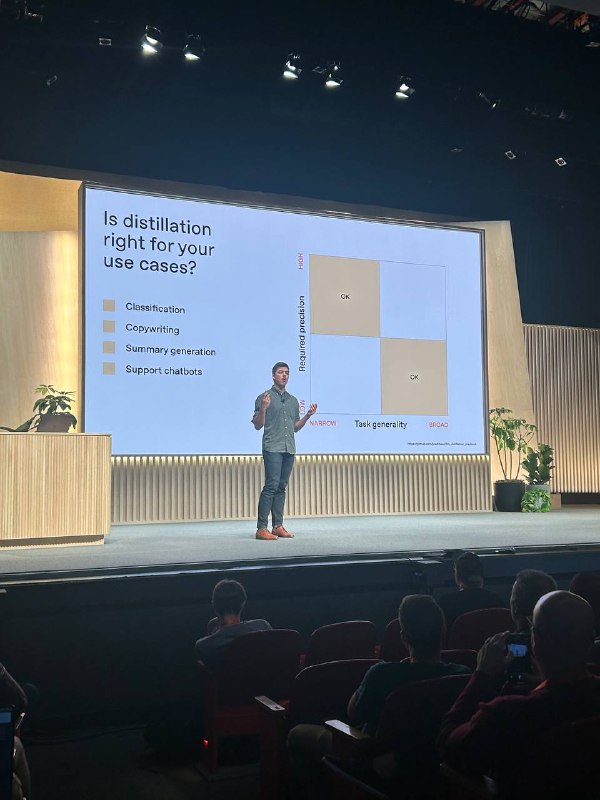
Где она подходит:
• Классификация
• Копирайтинг
• Генерация резюме
• Чат-боты поддержки
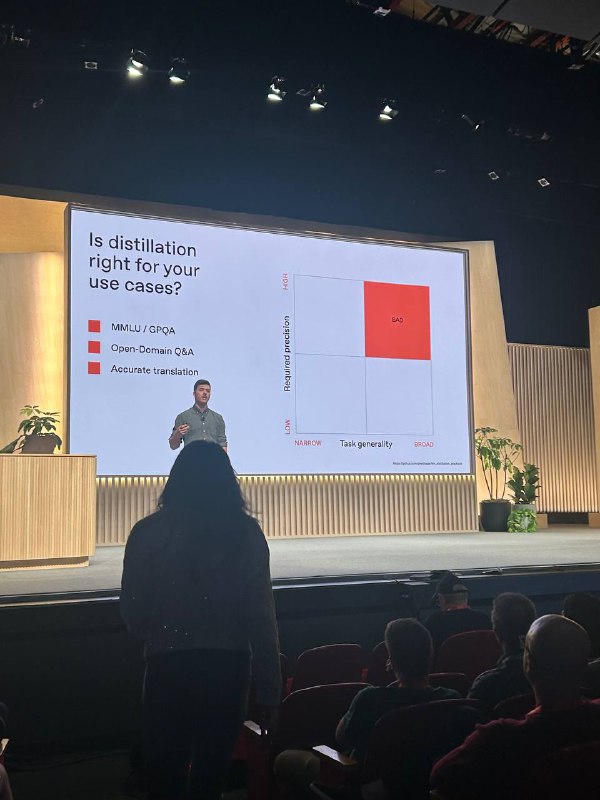
Где она не работает:
• Тесты MMLU/GPQA
• Вопросно-ответные системы открытого домена
• Точный перевод
Основные ошибки
• Неправильное распределение данных
• Слишком малое количество примеров
Как повысить эффективность дистилляции:
• Оптимизируйте большую модель
• Качественно подберите обучающие данные
• Не переусердствуйте с количеством примеров — достаточно нескольких тысяч.
• Работайте итеративно: оценивайте и улучшайте модель постепенно.
Дистилляция — это способ создать мощные и узкоспециализированные AI-решения, которые легко и быстро адаптируются под конкретные задачи, снижая затраты и увеличивая производительность.
Дистилляция моделей — это путь от прототипа к масштабированию. При использовании крупных моделей, таких как GPT-4o, разработчики сталкиваются с проблемами: время отклика, лимиты на запросы и высокая стоимость. Например, GPT-4o набирает 88% на MMLU, а его уменьшенная версия GPT-4o Mini — 82%. Но важен ли этот показатель для реальных задач?
Дистилляция: узкий фокус вместо широкого интеллекта
Большие модели часто превосходят по академическим метрикам, но такие тесты не всегда отражают реальные потребности пользователей. Здесь на сцену выходит дистилляция: не нужн широкий интеллект, а только узкий. Мы обучаем меньшую модель на основе данных, сгенерированных большой моделью.
Как это работает:
1 Оценка задач: Определение критериев, по которым модель будет оцениваться.
2 Сбор данных: Запись качественных ответов большой модели.
3 Файнтюнинг: Обучение маленькой модели на этих данных.
Основные сложности
На практике только около 15% разработчиков используют API для файнтюнинга. Главная сложность — создание качественного набора данных для обучения. Однако OpenAI представила два новых инструмента, которые упрощают этот процесс:
1 Stored Completions: Сохранение ответов моделей с параметром store=True.
2 Evals (beta): Оценка производительности модели прямо в интерфейсе Playground.
Теперь вы можете сохранять все выходные данные большой модели и добавлять метаданные, такие как разделение на тест и обучение. Во вкладке Evals можно настроить критерии оценки и сразу видеть результаты. Этот новый инструмент значительно упрощает процесс.
Дистилляция GPT-4o в GPT-4o-mini
Процесс дистилляции прост:
• Определите критерии оценки
• Сохраните результаты большой модели
• Нажмите "Distill" и выберите GPT-4o-mini в качестве базовой модели.
Через некоторое время вы получите настроенную модель, которая работает немного хуже GPT-4o, но значительно легче и дешевле в использовании.
Примеры и рекомендации
Где дистилляция наиболее эффективна:
• Анализ тональности
• Извлечение сущностей
• Майндинг мнений
Где она подходит:
• Классификация
• Копирайтинг
• Генерация резюме
• Чат-боты поддержки
Где она не работает:
• Тесты MMLU/GPQA
• Вопросно-ответные системы открытого домена
• Точный перевод
Основные ошибки
• Неправильное распределение данных
• Слишком малое количество примеров
Как повысить эффективность дистилляции:
• Оптимизируйте большую модель
• Качественно подберите обучающие данные
• Не переусердствуйте с количеством примеров — достаточно нескольких тысяч.
• Работайте итеративно: оценивайте и улучшайте модель постепенно.
Дистилляция — это способ создать мощные и узкоспециализированные AI-решения, которые легко и быстро адаптируются под конкретные задачи, снижая затраты и увеличивая производительность.
👍10❤8😐5🔥2
tgoop.com/nn_for_science/2186
Create:
Last Update:
Last Update:
Мощные небольшие модели с помощью дистилляции
Дистилляция моделей — это путь от прототипа к масштабированию. При использовании крупных моделей, таких как GPT-4o, разработчики сталкиваются с проблемами: время отклика, лимиты на запросы и высокая стоимость. Например, GPT-4o набирает 88% на MMLU, а его уменьшенная версия GPT-4o Mini — 82%. Но важен ли этот показатель для реальных задач?
Дистилляция: узкий фокус вместо широкого интеллекта
Большие модели часто превосходят по академическим метрикам, но такие тесты не всегда отражают реальные потребности пользователей. Здесь на сцену выходит дистилляция: не нужн широкий интеллект, а только узкий. Мы обучаем меньшую модель на основе данных, сгенерированных большой моделью.
Как это работает:
1 Оценка задач: Определение критериев, по которым модель будет оцениваться.
2 Сбор данных: Запись качественных ответов большой модели.
3 Файнтюнинг: Обучение маленькой модели на этих данных.
Основные сложности
На практике только около 15% разработчиков используют API для файнтюнинга. Главная сложность — создание качественного набора данных для обучения. Однако OpenAI представила два новых инструмента, которые упрощают этот процесс:
1 Stored Completions: Сохранение ответов моделей с параметром store=True.
2 Evals (beta): Оценка производительности модели прямо в интерфейсе Playground.
Теперь вы можете сохранять все выходные данные большой модели и добавлять метаданные, такие как разделение на тест и обучение. Во вкладке Evals можно настроить критерии оценки и сразу видеть результаты. Этот новый инструмент значительно упрощает процесс.
Дистилляция GPT-4o в GPT-4o-mini
Процесс дистилляции прост:
• Определите критерии оценки
• Сохраните результаты большой модели
• Нажмите "Distill" и выберите GPT-4o-mini в качестве базовой модели.
Через некоторое время вы получите настроенную модель, которая работает немного хуже GPT-4o, но значительно легче и дешевле в использовании.
Примеры и рекомендации
Где дистилляция наиболее эффективна:
• Анализ тональности
• Извлечение сущностей
• Майндинг мнений
Где она подходит:
• Классификация
• Копирайтинг
• Генерация резюме
• Чат-боты поддержки
Где она не работает:
• Тесты MMLU/GPQA
• Вопросно-ответные системы открытого домена
• Точный перевод
Основные ошибки
• Неправильное распределение данных
• Слишком малое количество примеров
Как повысить эффективность дистилляции:
• Оптимизируйте большую модель
• Качественно подберите обучающие данные
• Не переусердствуйте с количеством примеров — достаточно нескольких тысяч.
• Работайте итеративно: оценивайте и улучшайте модель постепенно.
Дистилляция — это способ создать мощные и узкоспециализированные AI-решения, которые легко и быстро адаптируются под конкретные задачи, снижая затраты и увеличивая производительность.
Дистилляция моделей — это путь от прототипа к масштабированию. При использовании крупных моделей, таких как GPT-4o, разработчики сталкиваются с проблемами: время отклика, лимиты на запросы и высокая стоимость. Например, GPT-4o набирает 88% на MMLU, а его уменьшенная версия GPT-4o Mini — 82%. Но важен ли этот показатель для реальных задач?
Дистилляция: узкий фокус вместо широкого интеллекта
Большие модели часто превосходят по академическим метрикам, но такие тесты не всегда отражают реальные потребности пользователей. Здесь на сцену выходит дистилляция: не нужн широкий интеллект, а только узкий. Мы обучаем меньшую модель на основе данных, сгенерированных большой моделью.
Как это работает:
1 Оценка задач: Определение критериев, по которым модель будет оцениваться.
2 Сбор данных: Запись качественных ответов большой модели.
3 Файнтюнинг: Обучение маленькой модели на этих данных.
Основные сложности
На практике только около 15% разработчиков используют API для файнтюнинга. Главная сложность — создание качественного набора данных для обучения. Однако OpenAI представила два новых инструмента, которые упрощают этот процесс:
1 Stored Completions: Сохранение ответов моделей с параметром store=True.
2 Evals (beta): Оценка производительности модели прямо в интерфейсе Playground.
Теперь вы можете сохранять все выходные данные большой модели и добавлять метаданные, такие как разделение на тест и обучение. Во вкладке Evals можно настроить критерии оценки и сразу видеть результаты. Этот новый инструмент значительно упрощает процесс.
Дистилляция GPT-4o в GPT-4o-mini
Процесс дистилляции прост:
• Определите критерии оценки
• Сохраните результаты большой модели
• Нажмите "Distill" и выберите GPT-4o-mini в качестве базовой модели.
Через некоторое время вы получите настроенную модель, которая работает немного хуже GPT-4o, но значительно легче и дешевле в использовании.
Примеры и рекомендации
Где дистилляция наиболее эффективна:
• Анализ тональности
• Извлечение сущностей
• Майндинг мнений
Где она подходит:
• Классификация
• Копирайтинг
• Генерация резюме
• Чат-боты поддержки
Где она не работает:
• Тесты MMLU/GPQA
• Вопросно-ответные системы открытого домена
• Точный перевод
Основные ошибки
• Неправильное распределение данных
• Слишком малое количество примеров
Как повысить эффективность дистилляции:
• Оптимизируйте большую модель
• Качественно подберите обучающие данные
• Не переусердствуйте с количеством примеров — достаточно нескольких тысяч.
• Работайте итеративно: оценивайте и улучшайте модель постепенно.
Дистилляция — это способ создать мощные и узкоспециализированные AI-решения, которые легко и быстро адаптируются под конкретные задачи, снижая затраты и увеличивая производительность.
BY AI для Всех







Share with your friend now:
tgoop.com/nn_for_science/2186