
Провел тесты новой LLaMA на нашем железе, а именно на сервере с 4090 в одиночном и х2 виде.
Сейчас выложу, что в итоге я получил на 24GB VRAM на одной 4090:
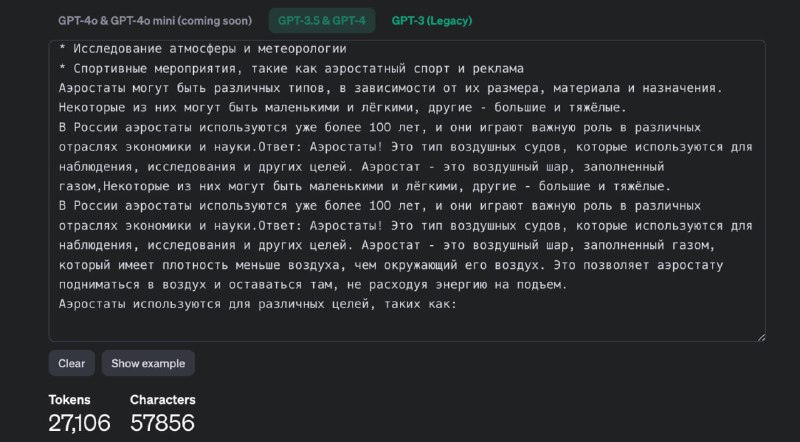
Имеем огромный бессмысленный текст на 27k токенов (так считает токенайзер OpenAI).
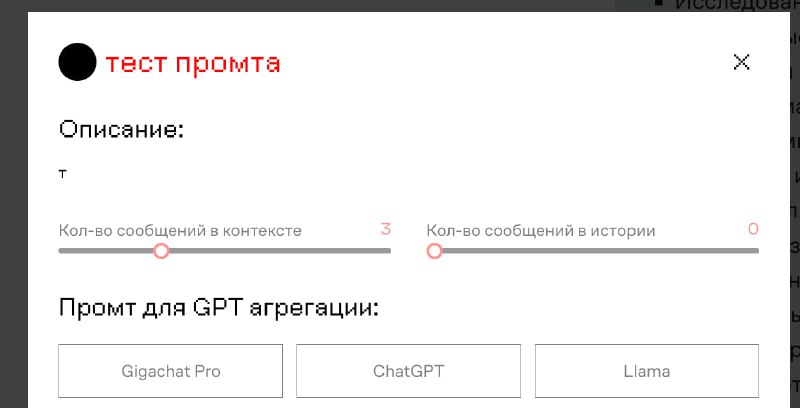
Имеем нашу RAG платформу. Включен классический поиск, в настройках контекста стоит промпт на 200 токенов + отдача топ 3 чанков (гибридный поиск отключен). История отключена.
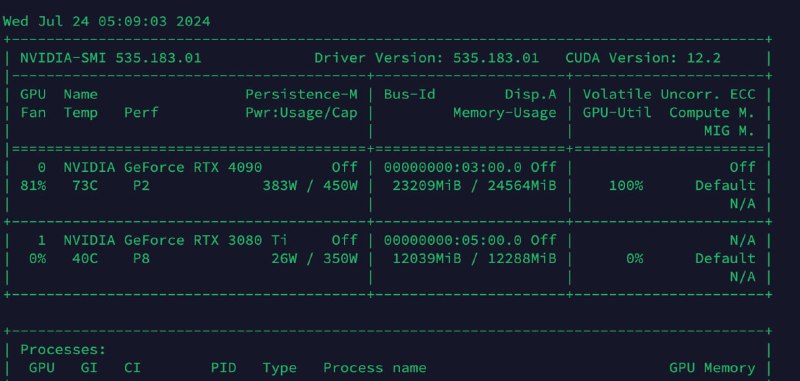
Далее кидаем это все в наш чат и получаем, что модель это "прожевала". Получаем утилизацию на 23GB, сверху от загрузки есть небольшой запас, но я по напутсвию из документов по vllm указал "--max-model-len", "18700".
Понимаю, что токенайзеры LLaMA и OpenAI считают по-разному, но если ориентироваться на их подсчеты, то теперь в наш RAG со всеми настройками помещается примерно 67+ тысяч символов, что составляет примерно 30 страниц документов.
Я знал, что не стоит упираться в обучение и поиск кастомных тюнов для увеличения контекста.
Далее сегодня проведу тесты на двух 4090 и расскажу, сколько контекста туда помещается, так как LLaMA 3.1 теперь поддерживает 128k контекста!
P.S пытался найти готовые калькуляторы но лучше уж проверить на практики! И на своем железе
Сейчас выложу, что в итоге я получил на 24GB VRAM на одной 4090:
Имеем огромный бессмысленный текст на 27k токенов (так считает токенайзер OpenAI).
Имеем нашу RAG платформу. Включен классический поиск, в настройках контекста стоит промпт на 200 токенов + отдача топ 3 чанков (гибридный поиск отключен). История отключена.
Далее кидаем это все в наш чат и получаем, что модель это "прожевала". Получаем утилизацию на 23GB, сверху от загрузки есть небольшой запас, но я по напутсвию из документов по vllm указал "--max-model-len", "18700".
Понимаю, что токенайзеры LLaMA и OpenAI считают по-разному, но если ориентироваться на их подсчеты, то теперь в наш RAG со всеми настройками помещается примерно 67+ тысяч символов, что составляет примерно 30 страниц документов.
Я знал, что не стоит упираться в обучение и поиск кастомных тюнов для увеличения контекста.
Далее сегодня проведу тесты на двух 4090 и расскажу, сколько контекста туда помещается, так как LLaMA 3.1 теперь поддерживает 128k контекста!
P.S пытался найти готовые калькуляторы но лучше уж проверить на практики! И на своем железе
🔥8❤1
tgoop.com/neuraldeep/984
Create:
Last Update:
Last Update:
Провел тесты новой LLaMA на нашем железе, а именно на сервере с 4090 в одиночном и х2 виде.
Сейчас выложу, что в итоге я получил на 24GB VRAM на одной 4090:
Имеем огромный бессмысленный текст на 27k токенов (так считает токенайзер OpenAI).
Имеем нашу RAG платформу. Включен классический поиск, в настройках контекста стоит промпт на 200 токенов + отдача топ 3 чанков (гибридный поиск отключен). История отключена.
Далее кидаем это все в наш чат и получаем, что модель это "прожевала". Получаем утилизацию на 23GB, сверху от загрузки есть небольшой запас, но я по напутсвию из документов по vllm указал "--max-model-len", "18700".
Понимаю, что токенайзеры LLaMA и OpenAI считают по-разному, но если ориентироваться на их подсчеты, то теперь в наш RAG со всеми настройками помещается примерно 67+ тысяч символов, что составляет примерно 30 страниц документов.
Я знал, что не стоит упираться в обучение и поиск кастомных тюнов для увеличения контекста.
Далее сегодня проведу тесты на двух 4090 и расскажу, сколько контекста туда помещается, так как LLaMA 3.1 теперь поддерживает 128k контекста!
P.S пытался найти готовые калькуляторы но лучше уж проверить на практики! И на своем железе
Сейчас выложу, что в итоге я получил на 24GB VRAM на одной 4090:
Имеем огромный бессмысленный текст на 27k токенов (так считает токенайзер OpenAI).
Имеем нашу RAG платформу. Включен классический поиск, в настройках контекста стоит промпт на 200 токенов + отдача топ 3 чанков (гибридный поиск отключен). История отключена.
Далее кидаем это все в наш чат и получаем, что модель это "прожевала". Получаем утилизацию на 23GB, сверху от загрузки есть небольшой запас, но я по напутсвию из документов по vllm указал "--max-model-len", "18700".
Понимаю, что токенайзеры LLaMA и OpenAI считают по-разному, но если ориентироваться на их подсчеты, то теперь в наш RAG со всеми настройками помещается примерно 67+ тысяч символов, что составляет примерно 30 страниц документов.
Я знал, что не стоит упираться в обучение и поиск кастомных тюнов для увеличения контекста.
Далее сегодня проведу тесты на двух 4090 и расскажу, сколько контекста туда помещается, так как LLaMA 3.1 теперь поддерживает 128k контекста!
P.S пытался найти готовые калькуляторы но лучше уж проверить на практики! И на своем железе
BY Neural Deep
Share with your friend now:
tgoop.com/neuraldeep/984