
С вами на связи @Vakovalskii
И я давно провожу большое кол-во экспериментов с LLM и GenAI но только сейчас дошли руки начать оформлять это все в записи, и так начнем
Я хочу говорить с LLM в реальном времени через браузер или по телефону.
Проблема? В целом, да
В чем? Во времени ответа!
До сих пор OpenAI не выпустила функцию общения с Omni.
А в сети есть какой-то стартап, где ребята обучили мультимодальную LLM, но она несет дикую дичь.
Что имею я в своем арсенале? Доступ к 10+ репозиториям для открытого использования сервисов:
- STT (речь в текст)
- LLM (можно сказать, GPT-3.5)
- TTS (текст в речь)
А дальше что?
Попробуем все собрать в какую-то архитектуру. Получил 6-8 секунд на ответ (ну здорово, такого на GitHub около 20-30 репозиториев).
А дальше что?
Я понял, что записывать все, что слышит микрофон, как-то дико, и нужно что-то придумать!
Обратившись к документации, я понял, что все используют сервисы VAD (voice activity detection). Они определяют, есть ли в текущих звуках вокруг речь, и делают это достаточно быстро (спойлер: домашние ассистенты используют эти библиотеки на борту).
LLM надо квантовать и сделать легче (готово взяли llama3-4bit)
Надо найти самы быстрый STT
Найдо найти и протестировать самый быстрый TTS
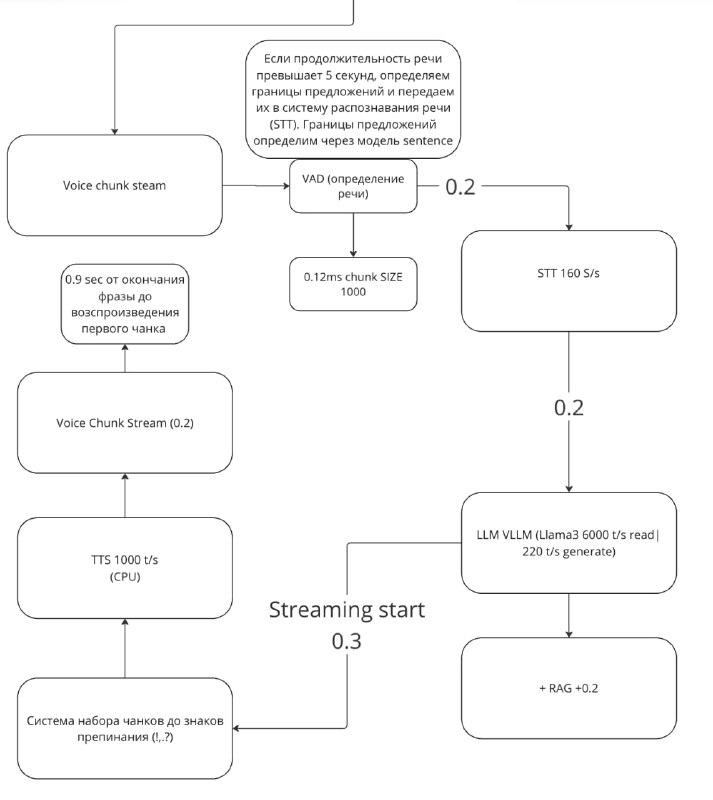
И родилась новая архитектура. (рис1)
На ней есть все по кругу и с задержками, что я замерил. Самое главное, что я взял сервер, который ближе всего ко мне, почти локально в серверной москвы.
Ну что я получил на выходе?
0.2 секунды на распознавание речи
0.5 секунд на RAG + LLM
0.3 секунды на то, что LLM начнет мне стримить свой вывод, как бы печатать
0.2 секунды на озвучку речи по чанкам
Итого 1.2 секунды, и если взять сеть, то 1.5-2 секунды от момента, когда я закончил говорить, до момента, когда я услышу первый звук от своих колонок.
В следующих версиях я хочу научить систему понимать, что я её хочу прервать, и заставить её позвонить мне на телефон.
Но самое интересное что клиент уже находится не локально а общается по API со всеми сервисами
Тесты мои
Текст мой
Голос мой
=)
И я давно провожу большое кол-во экспериментов с LLM и GenAI но только сейчас дошли руки начать оформлять это все в записи, и так начнем
Я хочу говорить с LLM в реальном времени через браузер или по телефону.
Проблема? В целом, да
В чем? Во времени ответа!
До сих пор OpenAI не выпустила функцию общения с Omni.
А в сети есть какой-то стартап, где ребята обучили мультимодальную LLM, но она несет дикую дичь.
Что имею я в своем арсенале? Доступ к 10+ репозиториям для открытого использования сервисов:
- STT (речь в текст)
- LLM (можно сказать, GPT-3.5)
- TTS (текст в речь)
А дальше что?
Попробуем все собрать в какую-то архитектуру. Получил 6-8 секунд на ответ (ну здорово, такого на GitHub около 20-30 репозиториев).
А дальше что?
Я понял, что записывать все, что слышит микрофон, как-то дико, и нужно что-то придумать!
Обратившись к документации, я понял, что все используют сервисы VAD (voice activity detection). Они определяют, есть ли в текущих звуках вокруг речь, и делают это достаточно быстро (спойлер: домашние ассистенты используют эти библиотеки на борту).
LLM надо квантовать и сделать легче (готово взяли llama3-4bit)
Надо найти самы быстрый STT
Найдо найти и протестировать самый быстрый TTS
И родилась новая архитектура. (рис1)
На ней есть все по кругу и с задержками, что я замерил. Самое главное, что я взял сервер, который ближе всего ко мне, почти локально в серверной москвы.
Ну что я получил на выходе?
0.2 секунды на распознавание речи
0.5 секунд на RAG + LLM
0.3 секунды на то, что LLM начнет мне стримить свой вывод, как бы печатать
0.2 секунды на озвучку речи по чанкам
Итого 1.2 секунды, и если взять сеть, то 1.5-2 секунды от момента, когда я закончил говорить, до момента, когда я услышу первый звук от своих колонок.
В следующих версиях я хочу научить систему понимать, что я её хочу прервать, и заставить её позвонить мне на телефон.
Но самое интересное что клиент уже находится не локально а общается по API со всеми сервисами
Тесты мои
Текст мой
Голос мой
=)
🔥16
tgoop.com/neuraldeep/977
Create:
Last Update:
Last Update:
С вами на связи @Vakovalskii
И я давно провожу большое кол-во экспериментов с LLM и GenAI но только сейчас дошли руки начать оформлять это все в записи, и так начнем
Я хочу говорить с LLM в реальном времени через браузер или по телефону.
Проблема? В целом, да
В чем? Во времени ответа!
До сих пор OpenAI не выпустила функцию общения с Omni.
А в сети есть какой-то стартап, где ребята обучили мультимодальную LLM, но она несет дикую дичь.
Что имею я в своем арсенале? Доступ к 10+ репозиториям для открытого использования сервисов:
- STT (речь в текст)
- LLM (можно сказать, GPT-3.5)
- TTS (текст в речь)
А дальше что?
Попробуем все собрать в какую-то архитектуру. Получил 6-8 секунд на ответ (ну здорово, такого на GitHub около 20-30 репозиториев).
А дальше что?
Я понял, что записывать все, что слышит микрофон, как-то дико, и нужно что-то придумать!
Обратившись к документации, я понял, что все используют сервисы VAD (voice activity detection). Они определяют, есть ли в текущих звуках вокруг речь, и делают это достаточно быстро (спойлер: домашние ассистенты используют эти библиотеки на борту).
LLM надо квантовать и сделать легче (готово взяли llama3-4bit)
Надо найти самы быстрый STT
Найдо найти и протестировать самый быстрый TTS
И родилась новая архитектура. (рис1)
На ней есть все по кругу и с задержками, что я замерил. Самое главное, что я взял сервер, который ближе всего ко мне, почти локально в серверной москвы.
Ну что я получил на выходе?
0.2 секунды на распознавание речи
0.5 секунд на RAG + LLM
0.3 секунды на то, что LLM начнет мне стримить свой вывод, как бы печатать
0.2 секунды на озвучку речи по чанкам
Итого 1.2 секунды, и если взять сеть, то 1.5-2 секунды от момента, когда я закончил говорить, до момента, когда я услышу первый звук от своих колонок.
В следующих версиях я хочу научить систему понимать, что я её хочу прервать, и заставить её позвонить мне на телефон.
Но самое интересное что клиент уже находится не локально а общается по API со всеми сервисами
Тесты мои
Текст мой
Голос мой
=)
И я давно провожу большое кол-во экспериментов с LLM и GenAI но только сейчас дошли руки начать оформлять это все в записи, и так начнем
Я хочу говорить с LLM в реальном времени через браузер или по телефону.
Проблема? В целом, да
В чем? Во времени ответа!
До сих пор OpenAI не выпустила функцию общения с Omni.
А в сети есть какой-то стартап, где ребята обучили мультимодальную LLM, но она несет дикую дичь.
Что имею я в своем арсенале? Доступ к 10+ репозиториям для открытого использования сервисов:
- STT (речь в текст)
- LLM (можно сказать, GPT-3.5)
- TTS (текст в речь)
А дальше что?
Попробуем все собрать в какую-то архитектуру. Получил 6-8 секунд на ответ (ну здорово, такого на GitHub около 20-30 репозиториев).
А дальше что?
Я понял, что записывать все, что слышит микрофон, как-то дико, и нужно что-то придумать!
Обратившись к документации, я понял, что все используют сервисы VAD (voice activity detection). Они определяют, есть ли в текущих звуках вокруг речь, и делают это достаточно быстро (спойлер: домашние ассистенты используют эти библиотеки на борту).
LLM надо квантовать и сделать легче (готово взяли llama3-4bit)
Надо найти самы быстрый STT
Найдо найти и протестировать самый быстрый TTS
И родилась новая архитектура. (рис1)
На ней есть все по кругу и с задержками, что я замерил. Самое главное, что я взял сервер, который ближе всего ко мне, почти локально в серверной москвы.
Ну что я получил на выходе?
0.2 секунды на распознавание речи
0.5 секунд на RAG + LLM
0.3 секунды на то, что LLM начнет мне стримить свой вывод, как бы печатать
0.2 секунды на озвучку речи по чанкам
Итого 1.2 секунды, и если взять сеть, то 1.5-2 секунды от момента, когда я закончил говорить, до момента, когда я услышу первый звук от своих колонок.
В следующих версиях я хочу научить систему понимать, что я её хочу прервать, и заставить её позвонить мне на телефон.
Но самое интересное что клиент уже находится не локально а общается по API со всеми сервисами
Тесты мои
Текст мой
Голос мой
=)
BY Neural Deep
Share with your friend now:
tgoop.com/neuraldeep/977