
tgoop.com/neuraldeep/1409
Last Update:
1M контекст - фейк? Тесты NoLiMa показали что RAG на длинных контекстах почти мертв? 💀
Наткнулся на интересное исследование Adobe Research про новый бенчмарк NoLiMa (Long-Context Evaluation Beyond Literal Matching)
В отличие от классического подхода "иголка в стоге сена", здесь тестируется способность модели работать с контекстом когда нет прямых лексических совпадений
Что такое NoLiMa и чем отличается?
Классические тесты (needle-in-haystack) позволяют моделям искать прямые совпадения слов
NoLiMa заставляет модель делать семантические связи без прямых текстовых совпадений
Требует от модели более глубокого понимания контекста и ассоциативного мышления
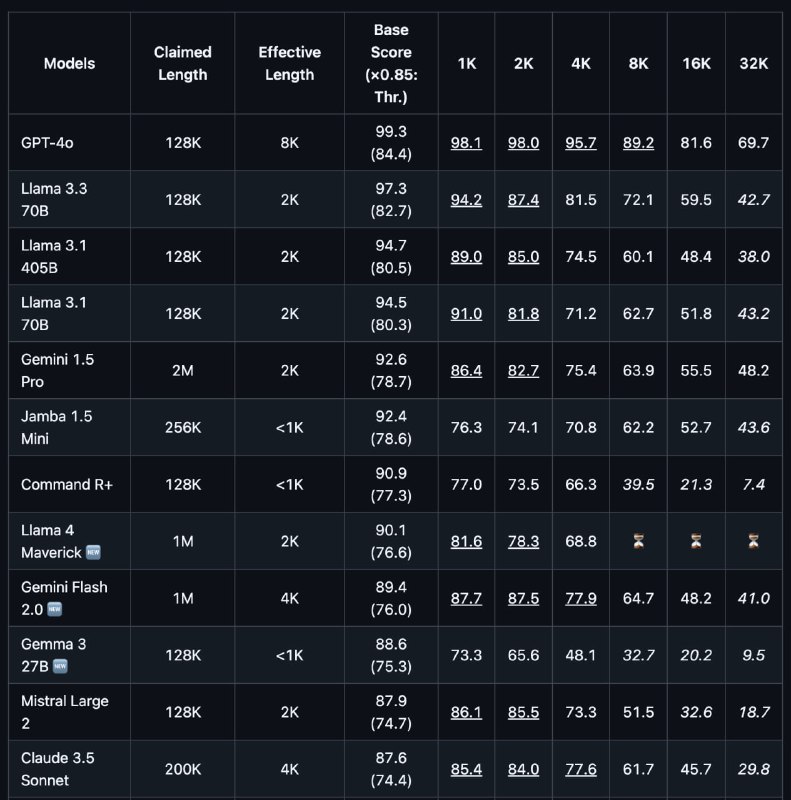
- Протестировано 12+ моделей с поддержкой контекста от 128K до 10M токенов
- Даже топовые модели значительно деградируют на длинных контекстах
- GPT-4o падает с 99.3% на коротких контекстах до 69.7% на 32K
У большинства моделей провал производительности ниже 50% от базового результата
| Модель | Заяв.| Эфф| Score | 4K |
|-------------|-----------|-------|-------|
| GPT-4o | 128K | 8K | 99.3% | 95.7% |
| Llama 3.3 ..| 128K | 2K | 97.3% | 81.5% |
| Llama 4 Ma..| 1M | 2K | 90.1% | 68.8% |
| Gemini 1.5 .| 2M | 2K | 92.6% | 75.4% |
| Claude 3.5..| 200K | 4K | 87.6% | 77.6% |
Почему это важно для наших RAG систем?
В реальном мире информация редко лежит в тексте буквально
Чаще нам нужна модель, способная делать выводы из контекста, находить скрытые связи и работать с разными формулировками одной и той же мысли
Эффективный контекст большинства моделей составляет ~4K токенов, что существенно ниже заявленных значений
Реальные кейсы обычно требуют работы с гораздо большими объемами текста
Что особенно интересно
Отдельно авторы тестировали модели с CoT/reasoning, и результаты обнадеживают:
- GPT-o1 (рассуждающая версия) показывает 31.1% на 32K против базового 18.9% у GPT-o3 Mini
- Llama 3.3 70B с CoT улучшила результат с 8.9% до 10.1% на сложном варианте теста
Stay tuned!
Буду следить за развитием темы, похоже что NoLiMa может стать новым стандартом для оценки RAG и других систем работы с длинным контекстом 💪
BY Neural Deep
Share with your friend now:
tgoop.com/neuraldeep/1409