
tgoop.com/neuraldeep/1359
Last Update:
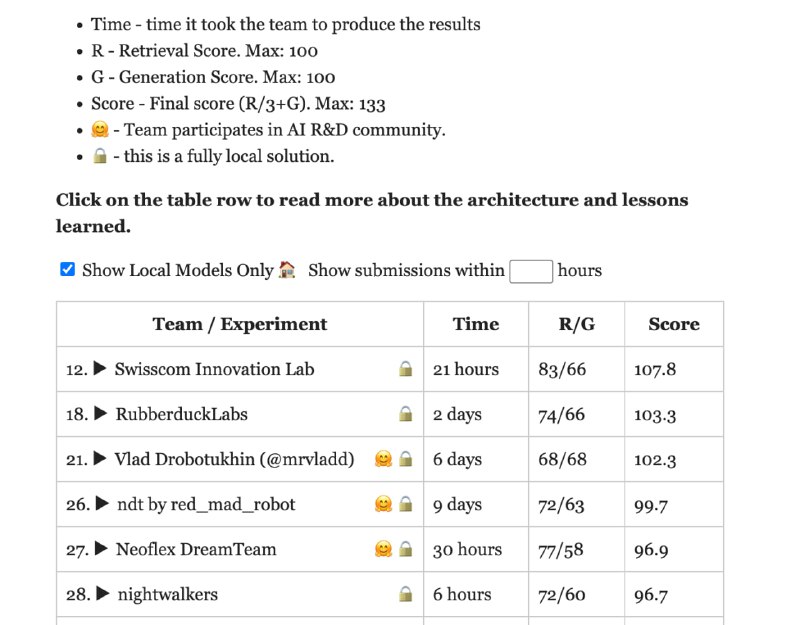
Результаты Enterprise RAG challenge (https://abdullin.com/erc/)
На сайте клацаем кнопку Show Local Models Only
На сегодня я завершаю свои исследования по локальным RAG подходам по документам и расскажу как мы заняли 4 место с разницей в 8 баллов от 70+b моделек (Локальных) и 1 первое место среди 32b моделей и Full Dense retrieval and cross-encoder reranker подходом (никаких кстати langchain и другого готового рагоделья только вайб кодинг в курсор и requests + vLLM)
Предыдущие посты на эту тему:
1) Анализ разных векторных моделек
2) Сравнение локальных моделей векторизации с 1 местом
3) Первые эксперименты
В итоге навайбкодил около 11к строк кода которые позволили показать такие результаты
Важное отступление что более 7 дней у меня в итоге заняло эксперименты по экстракту данных из PDF (карл)
И так для начала какое решение я принял сразу что-то ошибочно:
1) Никакой подготовки стендов заранее, все материалы команда и я в частности приступили изучать в день старта соревнований (взял из команды 2 человек ребята помогли вчитаться в условия и понять данные) (Вот тут рефлексия что нужно выделять как минимум неделю заранее свою что бы войти в курс дела)
2) Заранее пополнили все нужные нам сервисы для аренды локальных мощностей
3) Выкинул наш пайплайн RAG и я его стал строить с 0
4) Были заранее развернуты и заготовлены cross encoder bge-rerank + bge-m3 embedding model Арендована машина с А100 для (qwen 2.5 32b (16FP) instruct)
Первый этап парсинг данных из PDF
тут не обошлось без приключений так как внутри компании мы сконцентрировались на интеграциях к конфлюенс и системам для забора данных на документах мы давно не делали акцент по этому пошли гуглить и перебирать что же сможет нам достоверно достать данные из PDF
Перебрав около 3-5 библиотек финальный результат был сделан на библиотеке Marker
Далее чанкование и векторизация
Ничего нового каждая страница была разбита на чанки по 400 токенов с перекрытием в 80 токенов и дальше векторизирована батчами в сервис vLLM где развернута модель bge-m3
Далее под каждый док была созданная коллекция и настроены модели данных (что бы при запросе на KNN возвращать чанки номер страницы с которой он был взят и путь до файла где есть фулл контент страницы как потом я выяснил данный подход называется Parent Document Extraction)
Роутинг был заранее понятен из названия компаний и документов к ним в сабсет там были названя компаний их легко было смэтчить с документами(это я ксатит понял только почти в самом конце и выкинул роутинг совсем)
И так из приятного в сабсете(датасет) изначально указаны типы по этому были составлены через клод промпты под каждый тип запроса
Ну и пошли прогоны (прогонял я систему наверное раз 40 не менее)
Каждый раз вчитываясь что же она отвечает
Ищем чанки внутри дока через KNN
Ранжируем через bge-reranker (cross-encoder)
Передаем в ллм с CoT+SO для ответа
Были проблемы и с множественными вопросами но как показала моя практика курсор (в 20 итераций) смог учесть эти особенности и неплохо обработал этот формат
Как итог часть этих наработок уже ушла в наш прод продукт Smart Platform которая нацелена решать проблему создания RAG агентов для крупных компаний на локальных мощностях
Stay Tuned!
Скоро будет большой анонс нашей платформы будем с нашим CPO рассказывать что же мы там ваяли за год
P.S мы уже провели внутренние демо нашего продукта получили очень позитивный фидбек! Значит движемся куда нужно!
BY Neural Deep
Share with your friend now:
tgoop.com/neuraldeep/1359