
Enterprise RAG Challenge
Как всегда меня немного затянуло =)
Прямо сейчас участвую в Enterprise RAG Challenge от @llm_under_the_hood, и хочу рассказать, что pdf2md challenge почти в кармане.
В итоге я тестировал около 6 стратегий поиска информации
Разметка смог протестировать только одну стратегию, но и самую затратную она и заняла больше всего времени.
Я топлю за on-premise так что никаких облачных моделей все на своем железе благо мы в NDT закупились у теперь у нас есть 10 штук 4090 !
Итак, мы взяли все 100 PDF финансовых отчетов, это примерно ~14454 страниц
Из них было 3026
Общее кол-во категорий 13 (направлений)
1) Команда помогла найти топ библиотеку и конвертировала все PDF в markdown в текст.
2) Даже топ подход теряет около 2-5 % данных просто потому, что не видит кодировки или выводит ромбики. Сюда входят даже платные сервисы и самая топовая обработка
Все модели поднимаются в FP16 на vLMM
Векторная модель intfloat/multilingual-e5-large развернутая на 4 2080ti пропускная способность бешеная в 32 батч сайз
3) Я поднял наш весь свободный кластер и классифицировал все 14к страниц через 6 серверов с vLLM 4090 с развернутыми qwen 2 VL 7b instruct (это заняло примерно 2 часа времени)
На выход были вот такие:
4) Далее мы перевели все таблицы в markdown, img 2 markdown процесс занял у нас примерно 4 часа
5) Далее мы векторизировали часть данных (чанки + названия компаний, они были предоставлены в subset)
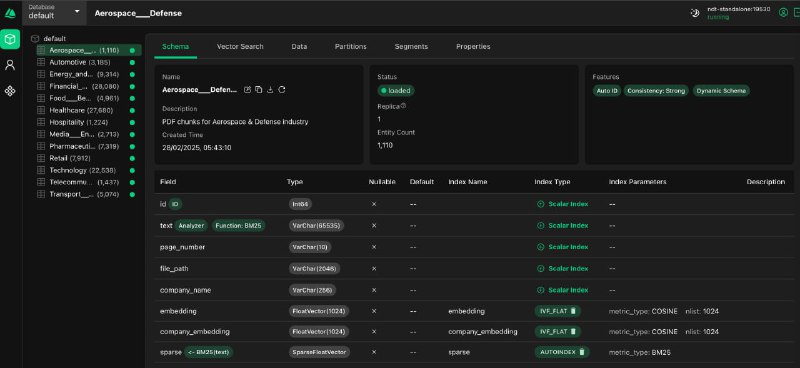
И загрузили в Milvus с вот такой схемой:
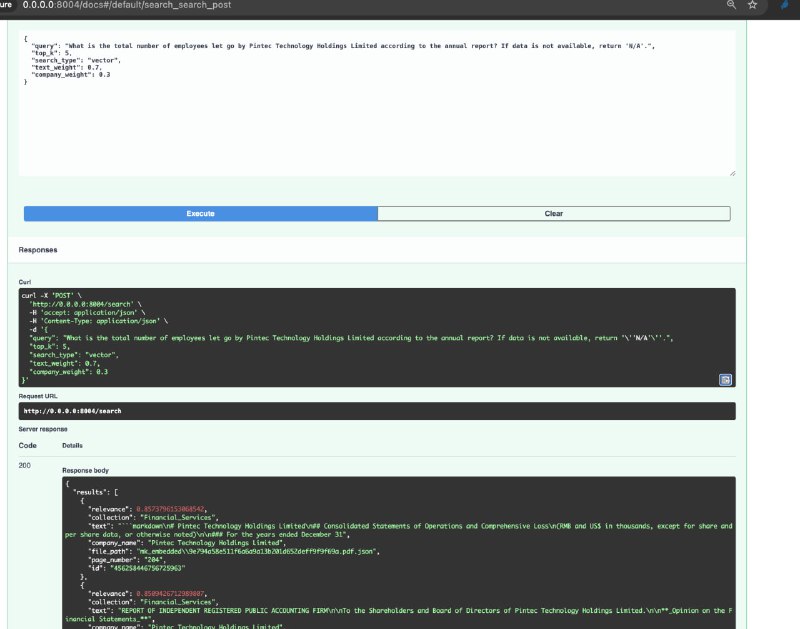
Сейчас, кстати 6 утра, и хорошо отрабатывает вот так поиск с подходом ANN search:
Самое важное, что при просмотре найденного контекста я беру топ 3 чанка и загружаю полные страницы из файловой системы:
Что хоро вижу четкую связь между названием компании, текстом и найденной страницей (достаточно близко), нет сильной разреженности
Ну и далее 4 схемы для SO в реквестах есть тип данных которые хотят видеть это упрощает жизнь, куда же без него:
И так далее для других типов под каждый типо свой промпт
На текущий момент прогнались все вопросы пошел глядеть и сабмитить!
Как всегда меня немного затянуло =)
Прямо сейчас участвую в Enterprise RAG Challenge от @llm_under_the_hood, и хочу рассказать, что pdf2md challenge почти в кармане.
В итоге я тестировал около 6 стратегий поиска информации
Разметка смог протестировать только одну стратегию, но и самую затратную она и заняла больше всего времени.
Я топлю за on-premise так что никаких облачных моделей все на своем железе благо мы в NDT закупились у теперь у нас есть 10 штук 4090 !
Итак, мы взяли все 100 PDF финансовых отчетов, это примерно ~14454 страниц
Из них было 3026
Общее кол-во категорий 13 (направлений)
1) Команда помогла найти топ библиотеку и конвертировала все PDF в markdown в текст.
2) Даже топ подход теряет около 2-5 % данных просто потому, что не видит кодировки или выводит ромбики. Сюда входят даже платные сервисы и самая топовая обработка
Все модели поднимаются в FP16 на vLMM
Векторная модель intfloat/multilingual-e5-large развернутая на 4 2080ti пропускная способность бешеная в 32 батч сайз
3) Я поднял наш весь свободный кластер и классифицировал все 14к страниц через 6 серверов с vLLM 4090 с развернутыми qwen 2 VL 7b instruct (это заняло примерно 2 часа времени)
На выход были вот такие:
"has_tables": true,
"table_count": 56,
"content_types": {
"image": 11,
"mixed_image_text": 11,
"chart": 3,
"text": 20,
"mixed_chart_text": 1,
"mixed_table_text": 33,
"table": 21
}
4) Далее мы перевели все таблицы в markdown, img 2 markdown процесс занял у нас примерно 4 часа
5) Далее мы векторизировали часть данных (чанки + названия компаний, они были предоставлены в subset)
И загрузили в Milvus с вот такой схемой:
{
"fields": [
{"name": "id", "type": "Int64"},
{"name": "text", "type": "VarChar(65535)"},
{"name": "page_number", "type": "VarChar(10)"},
{"name": "file_path", "type": "VarChar(2048)"},
{"name": "company_name", "type": "VarChar(256)"},
{"name": "embedding", "type": "FloatVector(1024)", "index": {"name": "embedding", "type": "COSINE", "nlist": 1024}},
{"name": "company_embedding", "type": "FloatVector(1024)", "index": {"name": "company_embedding", "type": "COSINE", "nlist": 1024}},
{"name": "sparse", "type": "SparseFloatVector", "index": {"name": "sparse", "type": "BM25"}}
]
}Сейчас, кстати 6 утра, и хорошо отрабатывает вот так поиск с подходом ANN search:
{
"query": "",
"top_k": 5,
"search_type": "vector",
"text_weight": 0.7,
"company_weight": 0.3
}Самое важное, что при просмотре найденного контекста я беру топ 3 чанка и загружаю полные страницы из файловой системы:
{
"results": [
{
"relevance": 0.8573796153068542,
"collection": "Financial_Services",
"text": "```markdown\n# Pintec Technology Holdings Limited\n## Consolidated Statements of Operations and Comprehensive Loss\n(RMB and US$ in thousands, except for share and per share data, or otherwise noted)\n\n### For the years ended December 31",
"company_name": "Pintec Technology Holdings Limited",
"file_path": "mk_embedded\\9e794a58e511f6a6a9a13b201d652deff9f9f69a.pdf.json",
"page_number": "204",
"id": "456258446756725963"
},Что хоро вижу четкую связь между названием компании, текстом и найденной страницей (достаточно близко), нет сильной разреженности
Ну и далее 4 схемы для SO в реквестах есть тип данных которые хотят видеть это упрощает жизнь, куда же без него:
NUMBER_SCHEMA = {
"type": "object",
"properties": {
"value": {"type": "string"},
"confidence": {"type": "number"},
"reasoning": {"type": "string"}
},
"required": ["value", "confidence", "reasoning"]
}BOOLEAN_SCHEMA = {
"type": "object",
"properties": {
"value": {"type": "boolean"},
"confidence": {"type": "number"},
"reasoning": {"type": "string"}
},
"required": ["value", "confidence", "reasoning"]
}И так далее для других типов под каждый типо свой промпт
На текущий момент прогнались все вопросы пошел глядеть и сабмитить!
tgoop.com/neuraldeep/1330
Create:
Last Update:
Last Update:
Enterprise RAG Challenge
Как всегда меня немного затянуло =)
Прямо сейчас участвую в Enterprise RAG Challenge от @llm_under_the_hood, и хочу рассказать, что pdf2md challenge почти в кармане.
В итоге я тестировал около 6 стратегий поиска информации
Разметка смог протестировать только одну стратегию, но и самую затратную она и заняла больше всего времени.
Я топлю за on-premise так что никаких облачных моделей все на своем железе благо мы в NDT закупились у теперь у нас есть 10 штук 4090 !
Итак, мы взяли все 100 PDF финансовых отчетов, это примерно ~14454 страниц
Из них было 3026
Общее кол-во категорий 13 (направлений)
1) Команда помогла найти топ библиотеку и конвертировала все PDF в markdown в текст.
2) Даже топ подход теряет около 2-5 % данных просто потому, что не видит кодировки или выводит ромбики. Сюда входят даже платные сервисы и самая топовая обработка
Все модели поднимаются в FP16 на vLMM
Векторная модель intfloat/multilingual-e5-large развернутая на 4 2080ti пропускная способность бешеная в 32 батч сайз
3) Я поднял наш весь свободный кластер и классифицировал все 14к страниц через 6 серверов с vLLM 4090 с развернутыми qwen 2 VL 7b instruct (это заняло примерно 2 часа времени)
На выход были вот такие:
4) Далее мы перевели все таблицы в markdown, img 2 markdown процесс занял у нас примерно 4 часа
5) Далее мы векторизировали часть данных (чанки + названия компаний, они были предоставлены в subset)
И загрузили в Milvus с вот такой схемой:
Сейчас, кстати 6 утра, и хорошо отрабатывает вот так поиск с подходом ANN search:
Самое важное, что при просмотре найденного контекста я беру топ 3 чанка и загружаю полные страницы из файловой системы:
Что хоро вижу четкую связь между названием компании, текстом и найденной страницей (достаточно близко), нет сильной разреженности
Ну и далее 4 схемы для SO в реквестах есть тип данных которые хотят видеть это упрощает жизнь, куда же без него:
И так далее для других типов под каждый типо свой промпт
На текущий момент прогнались все вопросы пошел глядеть и сабмитить!
Как всегда меня немного затянуло =)
Прямо сейчас участвую в Enterprise RAG Challenge от @llm_under_the_hood, и хочу рассказать, что pdf2md challenge почти в кармане.
В итоге я тестировал около 6 стратегий поиска информации
Разметка смог протестировать только одну стратегию, но и самую затратную она и заняла больше всего времени.
Я топлю за on-premise так что никаких облачных моделей все на своем железе благо мы в NDT закупились у теперь у нас есть 10 штук 4090 !
Итак, мы взяли все 100 PDF финансовых отчетов, это примерно ~14454 страниц
Из них было 3026
Общее кол-во категорий 13 (направлений)
1) Команда помогла найти топ библиотеку и конвертировала все PDF в markdown в текст.
2) Даже топ подход теряет около 2-5 % данных просто потому, что не видит кодировки или выводит ромбики. Сюда входят даже платные сервисы и самая топовая обработка
Все модели поднимаются в FP16 на vLMM
Векторная модель intfloat/multilingual-e5-large развернутая на 4 2080ti пропускная способность бешеная в 32 батч сайз
3) Я поднял наш весь свободный кластер и классифицировал все 14к страниц через 6 серверов с vLLM 4090 с развернутыми qwen 2 VL 7b instruct (это заняло примерно 2 часа времени)
На выход были вот такие:
"has_tables": true,
"table_count": 56,
"content_types": {
"image": 11,
"mixed_image_text": 11,
"chart": 3,
"text": 20,
"mixed_chart_text": 1,
"mixed_table_text": 33,
"table": 21
}
4) Далее мы перевели все таблицы в markdown, img 2 markdown процесс занял у нас примерно 4 часа
5) Далее мы векторизировали часть данных (чанки + названия компаний, они были предоставлены в subset)
И загрузили в Milvus с вот такой схемой:
{
"fields": [
{"name": "id", "type": "Int64"},
{"name": "text", "type": "VarChar(65535)"},
{"name": "page_number", "type": "VarChar(10)"},
{"name": "file_path", "type": "VarChar(2048)"},
{"name": "company_name", "type": "VarChar(256)"},
{"name": "embedding", "type": "FloatVector(1024)", "index": {"name": "embedding", "type": "COSINE", "nlist": 1024}},
{"name": "company_embedding", "type": "FloatVector(1024)", "index": {"name": "company_embedding", "type": "COSINE", "nlist": 1024}},
{"name": "sparse", "type": "SparseFloatVector", "index": {"name": "sparse", "type": "BM25"}}
]
}Сейчас, кстати 6 утра, и хорошо отрабатывает вот так поиск с подходом ANN search:
{
"query": "",
"top_k": 5,
"search_type": "vector",
"text_weight": 0.7,
"company_weight": 0.3
}Самое важное, что при просмотре найденного контекста я беру топ 3 чанка и загружаю полные страницы из файловой системы:
{
"results": [
{
"relevance": 0.8573796153068542,
"collection": "Financial_Services",
"text": "```markdown\n# Pintec Technology Holdings Limited\n## Consolidated Statements of Operations and Comprehensive Loss\n(RMB and US$ in thousands, except for share and per share data, or otherwise noted)\n\n### For the years ended December 31",
"company_name": "Pintec Technology Holdings Limited",
"file_path": "mk_embedded\\9e794a58e511f6a6a9a13b201d652deff9f9f69a.pdf.json",
"page_number": "204",
"id": "456258446756725963"
},Что хоро вижу четкую связь между названием компании, текстом и найденной страницей (достаточно близко), нет сильной разреженности
Ну и далее 4 схемы для SO в реквестах есть тип данных которые хотят видеть это упрощает жизнь, куда же без него:
NUMBER_SCHEMA = {
"type": "object",
"properties": {
"value": {"type": "string"},
"confidence": {"type": "number"},
"reasoning": {"type": "string"}
},
"required": ["value", "confidence", "reasoning"]
}BOOLEAN_SCHEMA = {
"type": "object",
"properties": {
"value": {"type": "boolean"},
"confidence": {"type": "number"},
"reasoning": {"type": "string"}
},
"required": ["value", "confidence", "reasoning"]
}И так далее для других типов под каждый типо свой промпт
На текущий момент прогнались все вопросы пошел глядеть и сабмитить!
BY Neural Deep
Share with your friend now:
tgoop.com/neuraldeep/1330