
Много шума касается маркета OpenAI. От себя скажу:
Вот статья к прочтению о том, что такое GPT's: https://habr.com/ru/articles/775070/.
Кратко, это удобный интерфейс для создания RAG без тонкой настройки.
Кому это полезно?
Как пример:
Небольшим бизнесам (малым продуктам) можно создать FAQ по продукту быстро и достаточно просто (обычный человек точно не справится, нужно разбираться в промптировании).
А теперь о проблемах.
Есть одна глобальная проблема у таких решений и несколько поменьше, а именно - точность. Веб-интерфейс OpenAI вам не поможет это решить при создании GPT's.
Мы сейчас с командой занимаемся разработкой альтернативных вариантов для улучшения точности в RAG-системах и уже внедрили первый пайплайн HyDE.
В чем суть?
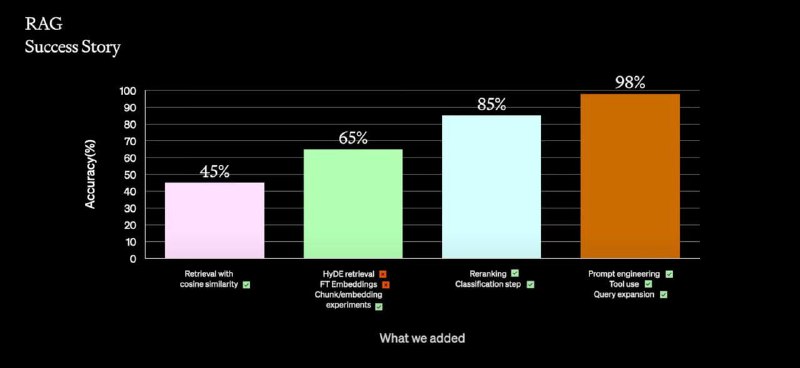
Если мы ищем данные в наших знаниях и пытаемся использовать LLM для анализа, то часто упускаем из виду, что неподготовленные данные и инструкции снижают точность работы такой системы до 45% и ниже.
Мы уже знаем, что нужно проверять и пробовать под конкретные задачи. Например, для нашей SmartBase мы разрабатываем инжиниринг промптов и чанк-эксперименты. Они уже завершились успешно: для узкого домена данных мы подняли точность до 90-97% полноты и качества ответов.
Это о том, что даже инструменты для создания GPT's сильно ограничены, когда мы хотим работать с уникальным доменом и требуется тонкая настройка.
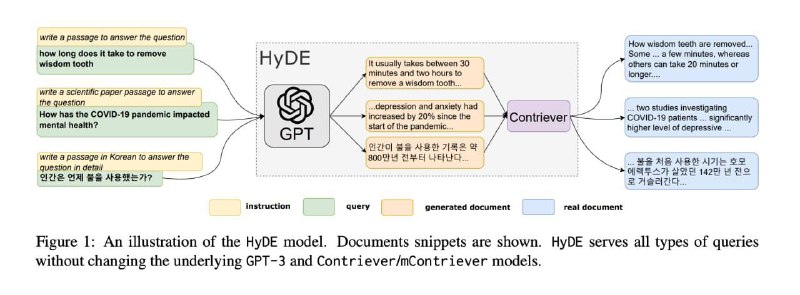
Сейчас мы проводим эксперименты с HyDE (Hypothetical Document Embeddings).
При стандартном RAG в качестве "ответов" служат документы из базы знаний, в качестве "запросов" - вопросы от пользователей. Есть гипотеза, что эмбеддинг вопроса и эмбеддинг ответа принадлежат разным семействам. По аналогии, ключи и значения в механизме внимания трансформеров - это разные вектора.
Вот статья к прочтению о том, что такое GPT's: https://habr.com/ru/articles/775070/.
Кратко, это удобный интерфейс для создания RAG без тонкой настройки.
Кому это полезно?
Как пример:
Небольшим бизнесам (малым продуктам) можно создать FAQ по продукту быстро и достаточно просто (обычный человек точно не справится, нужно разбираться в промптировании).
А теперь о проблемах.
Есть одна глобальная проблема у таких решений и несколько поменьше, а именно - точность. Веб-интерфейс OpenAI вам не поможет это решить при создании GPT's.
Мы сейчас с командой занимаемся разработкой альтернативных вариантов для улучшения точности в RAG-системах и уже внедрили первый пайплайн HyDE.
В чем суть?
Если мы ищем данные в наших знаниях и пытаемся использовать LLM для анализа, то часто упускаем из виду, что неподготовленные данные и инструкции снижают точность работы такой системы до 45% и ниже.
Мы уже знаем, что нужно проверять и пробовать под конкретные задачи. Например, для нашей SmartBase мы разрабатываем инжиниринг промптов и чанк-эксперименты. Они уже завершились успешно: для узкого домена данных мы подняли точность до 90-97% полноты и качества ответов.
Это о том, что даже инструменты для создания GPT's сильно ограничены, когда мы хотим работать с уникальным доменом и требуется тонкая настройка.
Сейчас мы проводим эксперименты с HyDE (Hypothetical Document Embeddings).
При стандартном RAG в качестве "ответов" служат документы из базы знаний, в качестве "запросов" - вопросы от пользователей. Есть гипотеза, что эмбеддинг вопроса и эмбеддинг ответа принадлежат разным семействам. По аналогии, ключи и значения в механизме внимания трансформеров - это разные вектора.
🔥6
tgoop.com/neuraldeep/125
Create:
Last Update:
Last Update:
Много шума касается маркета OpenAI. От себя скажу:
Вот статья к прочтению о том, что такое GPT's: https://habr.com/ru/articles/775070/.
Кратко, это удобный интерфейс для создания RAG без тонкой настройки.
Кому это полезно?
Как пример:
Небольшим бизнесам (малым продуктам) можно создать FAQ по продукту быстро и достаточно просто (обычный человек точно не справится, нужно разбираться в промптировании).
А теперь о проблемах.
Есть одна глобальная проблема у таких решений и несколько поменьше, а именно - точность. Веб-интерфейс OpenAI вам не поможет это решить при создании GPT's.
Мы сейчас с командой занимаемся разработкой альтернативных вариантов для улучшения точности в RAG-системах и уже внедрили первый пайплайн HyDE.
В чем суть?
Если мы ищем данные в наших знаниях и пытаемся использовать LLM для анализа, то часто упускаем из виду, что неподготовленные данные и инструкции снижают точность работы такой системы до 45% и ниже.
Мы уже знаем, что нужно проверять и пробовать под конкретные задачи. Например, для нашей SmartBase мы разрабатываем инжиниринг промптов и чанк-эксперименты. Они уже завершились успешно: для узкого домена данных мы подняли точность до 90-97% полноты и качества ответов.
Это о том, что даже инструменты для создания GPT's сильно ограничены, когда мы хотим работать с уникальным доменом и требуется тонкая настройка.
Сейчас мы проводим эксперименты с HyDE (Hypothetical Document Embeddings).
При стандартном RAG в качестве "ответов" служат документы из базы знаний, в качестве "запросов" - вопросы от пользователей. Есть гипотеза, что эмбеддинг вопроса и эмбеддинг ответа принадлежат разным семействам. По аналогии, ключи и значения в механизме внимания трансформеров - это разные вектора.
Вот статья к прочтению о том, что такое GPT's: https://habr.com/ru/articles/775070/.
Кратко, это удобный интерфейс для создания RAG без тонкой настройки.
Кому это полезно?
Как пример:
Небольшим бизнесам (малым продуктам) можно создать FAQ по продукту быстро и достаточно просто (обычный человек точно не справится, нужно разбираться в промптировании).
А теперь о проблемах.
Есть одна глобальная проблема у таких решений и несколько поменьше, а именно - точность. Веб-интерфейс OpenAI вам не поможет это решить при создании GPT's.
Мы сейчас с командой занимаемся разработкой альтернативных вариантов для улучшения точности в RAG-системах и уже внедрили первый пайплайн HyDE.
В чем суть?
Если мы ищем данные в наших знаниях и пытаемся использовать LLM для анализа, то часто упускаем из виду, что неподготовленные данные и инструкции снижают точность работы такой системы до 45% и ниже.
Мы уже знаем, что нужно проверять и пробовать под конкретные задачи. Например, для нашей SmartBase мы разрабатываем инжиниринг промптов и чанк-эксперименты. Они уже завершились успешно: для узкого домена данных мы подняли точность до 90-97% полноты и качества ответов.
Это о том, что даже инструменты для создания GPT's сильно ограничены, когда мы хотим работать с уникальным доменом и требуется тонкая настройка.
Сейчас мы проводим эксперименты с HyDE (Hypothetical Document Embeddings).
При стандартном RAG в качестве "ответов" служат документы из базы знаний, в качестве "запросов" - вопросы от пользователей. Есть гипотеза, что эмбеддинг вопроса и эмбеддинг ответа принадлежат разным семействам. По аналогии, ключи и значения в механизме внимания трансформеров - это разные вектора.
BY Neural Deep
Share with your friend now:
tgoop.com/neuraldeep/125