
Привет всем!
Хочу поделиться своими последними успехами в работе с LLama-3.1-70b в тему предыдущего поста
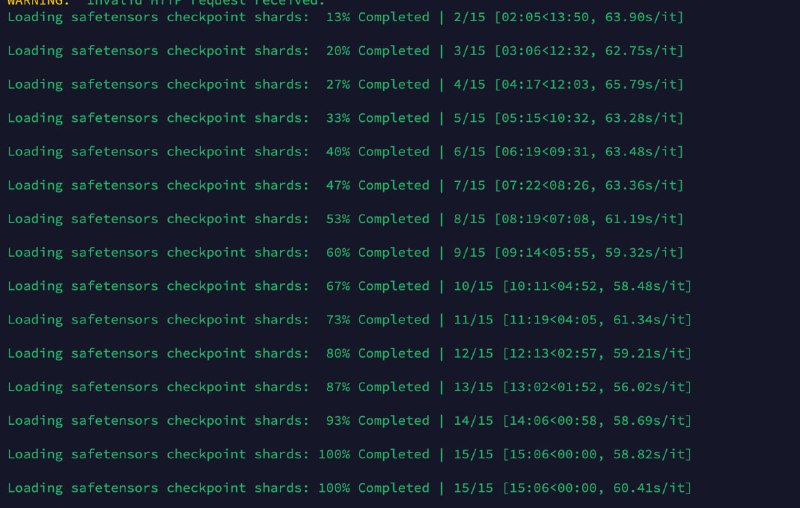
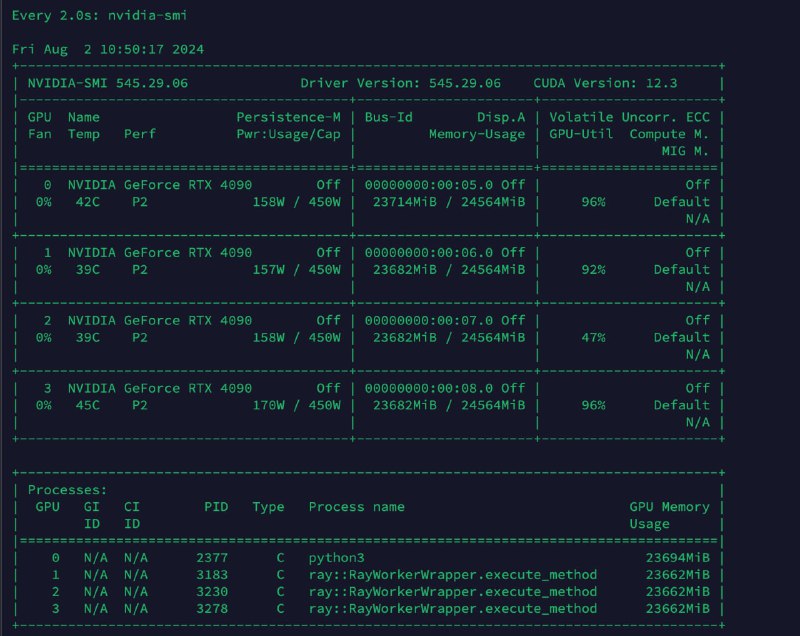
Удалось запустить LLama-3.1-70B в динамической квантизации FP8 на 16K контекста, и самое главное, это получилось сделать на четырёх картах 4090. Это круто, учитывая все заморочки с памятью и настройками и выделением места под кэш.
Но не всё было так гладко с самого начала. Когда я только начинал запускать модель, возникли проблемы с p2p конфигом, который создавался криво. Плюс, Ray бекенд для выполнения модели на нескольких карточках тоже не сразу заработал как надо. Я долго не мог понять, почему при 96 GB VRAM у меня не влезало больше 6K контекста. Это было реально грустно и не понятно.
После трёх или четырёх дней тестов и экспериментов я наконец-то нашёл оптимальный конфиг для запуска модели. Это было непросто, но результат того стоил.
Проведя кучу тестов по нашим RAG доменам, я понял, что текущий тест выбивает 100% точность, что делает его невалидным. Придётся придумать новый тест для более точной оценки.
Что касается возможностей модели, вот что мы проверили:
1. Обобщение текстов: Модель отлично справляется, точно следуя контексту.
2. Разметка текста: Тесты по разметке и NER (Named Entity Recognition) показали улучшение точности на 10-25%.
3. Работа в режиме агента с tool_use: Модель показала высокую эффективность, особенно при запоминании seed и 0 температуре, ошибка на тесте вызове тулзов составила 0 на 100 примерах запросов.
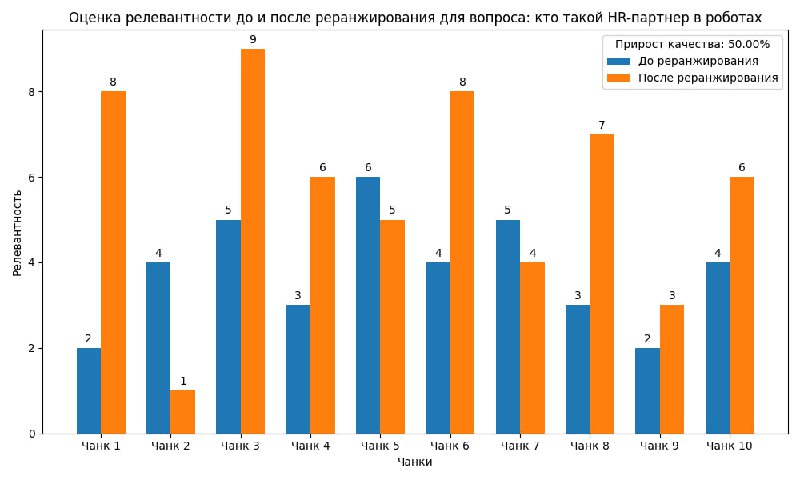
Также оценили работу модели re-ranking. В 9 из 10 случаев модель давала адекватную оценку релевантности чанков до и после реранжирования в RAG подходе.
Производительность модели оказалась следующей:
- Чтение: Средняя скорость обработки prompt — 1418.7 токенов в секунду, средняя скорость генерации — 0.5 токенов в секунду. Использование GPU KV cache — 34.4%
- Генерация: Средняя скорость обработки prompt — 0.0 токенов в секунду, средняя скорость генерации — 36.0 токенов в секунду. Использование GPU KV cache — 35.1%
Эти данные показывают, что нам ещё нужно искать подходы для ускорения генерации, чтобы добиться более высокой производительности.
И вот самое приятное: теперь сервер стоит не 1,5 миллиона рублей в месяц, а всего 240 тысяч рублей! Карл, это в 6 раз дешевле! Это огромная экономия, которая делает использование таких мощных моделей гораздо более доступным.
В общем, LLama-3.1-70B в динамической квантизации FP8 на 16K контекста на четырёх картах 4090 показала себя с лучшей стороны. Будем продолжать тестирование и оптимизацию, чтобы добиться ещё лучших результатов.
Прикладываю картинки:
1-2. Запуск на 4 4090 и нагрузка на сервер и его конфиги.
3. Тесты модели при проверке реранжирования.
Хочу поделиться своими последними успехами в работе с LLama-3.1-70b в тему предыдущего поста
Удалось запустить LLama-3.1-70B в динамической квантизации FP8 на 16K контекста, и самое главное, это получилось сделать на четырёх картах 4090. Это круто, учитывая все заморочки с памятью и настройками и выделением места под кэш.
Но не всё было так гладко с самого начала. Когда я только начинал запускать модель, возникли проблемы с p2p конфигом, который создавался криво. Плюс, Ray бекенд для выполнения модели на нескольких карточках тоже не сразу заработал как надо. Я долго не мог понять, почему при 96 GB VRAM у меня не влезало больше 6K контекста. Это было реально грустно и не понятно.
После трёх или четырёх дней тестов и экспериментов я наконец-то нашёл оптимальный конфиг для запуска модели. Это было непросто, но результат того стоил.
Проведя кучу тестов по нашим RAG доменам, я понял, что текущий тест выбивает 100% точность, что делает его невалидным. Придётся придумать новый тест для более точной оценки.
Что касается возможностей модели, вот что мы проверили:
1. Обобщение текстов: Модель отлично справляется, точно следуя контексту.
2. Разметка текста: Тесты по разметке и NER (Named Entity Recognition) показали улучшение точности на 10-25%.
3. Работа в режиме агента с tool_use: Модель показала высокую эффективность, особенно при запоминании seed и 0 температуре, ошибка на тесте вызове тулзов составила 0 на 100 примерах запросов.
Также оценили работу модели re-ranking. В 9 из 10 случаев модель давала адекватную оценку релевантности чанков до и после реранжирования в RAG подходе.
Производительность модели оказалась следующей:
- Чтение: Средняя скорость обработки prompt — 1418.7 токенов в секунду, средняя скорость генерации — 0.5 токенов в секунду. Использование GPU KV cache — 34.4%
- Генерация: Средняя скорость обработки prompt — 0.0 токенов в секунду, средняя скорость генерации — 36.0 токенов в секунду. Использование GPU KV cache — 35.1%
Эти данные показывают, что нам ещё нужно искать подходы для ускорения генерации, чтобы добиться более высокой производительности.
И вот самое приятное: теперь сервер стоит не 1,5 миллиона рублей в месяц, а всего 240 тысяч рублей! Карл, это в 6 раз дешевле! Это огромная экономия, которая делает использование таких мощных моделей гораздо более доступным.
В общем, LLama-3.1-70B в динамической квантизации FP8 на 16K контекста на четырёх картах 4090 показала себя с лучшей стороны. Будем продолжать тестирование и оптимизацию, чтобы добиться ещё лучших результатов.
Прикладываю картинки:
1-2. Запуск на 4 4090 и нагрузка на сервер и его конфиги.
3. Тесты модели при проверке реранжирования.
🔥8🤔4👍1
tgoop.com/neuraldeep/1013
Create:
Last Update:
Last Update:
Привет всем!
Хочу поделиться своими последними успехами в работе с LLama-3.1-70b в тему предыдущего поста
Удалось запустить LLama-3.1-70B в динамической квантизации FP8 на 16K контекста, и самое главное, это получилось сделать на четырёх картах 4090. Это круто, учитывая все заморочки с памятью и настройками и выделением места под кэш.
Но не всё было так гладко с самого начала. Когда я только начинал запускать модель, возникли проблемы с p2p конфигом, который создавался криво. Плюс, Ray бекенд для выполнения модели на нескольких карточках тоже не сразу заработал как надо. Я долго не мог понять, почему при 96 GB VRAM у меня не влезало больше 6K контекста. Это было реально грустно и не понятно.
После трёх или четырёх дней тестов и экспериментов я наконец-то нашёл оптимальный конфиг для запуска модели. Это было непросто, но результат того стоил.
Проведя кучу тестов по нашим RAG доменам, я понял, что текущий тест выбивает 100% точность, что делает его невалидным. Придётся придумать новый тест для более точной оценки.
Что касается возможностей модели, вот что мы проверили:
1. Обобщение текстов: Модель отлично справляется, точно следуя контексту.
2. Разметка текста: Тесты по разметке и NER (Named Entity Recognition) показали улучшение точности на 10-25%.
3. Работа в режиме агента с tool_use: Модель показала высокую эффективность, особенно при запоминании seed и 0 температуре, ошибка на тесте вызове тулзов составила 0 на 100 примерах запросов.
Также оценили работу модели re-ranking. В 9 из 10 случаев модель давала адекватную оценку релевантности чанков до и после реранжирования в RAG подходе.
Производительность модели оказалась следующей:
- Чтение: Средняя скорость обработки prompt — 1418.7 токенов в секунду, средняя скорость генерации — 0.5 токенов в секунду. Использование GPU KV cache — 34.4%
- Генерация: Средняя скорость обработки prompt — 0.0 токенов в секунду, средняя скорость генерации — 36.0 токенов в секунду. Использование GPU KV cache — 35.1%
Эти данные показывают, что нам ещё нужно искать подходы для ускорения генерации, чтобы добиться более высокой производительности.
И вот самое приятное: теперь сервер стоит не 1,5 миллиона рублей в месяц, а всего 240 тысяч рублей! Карл, это в 6 раз дешевле! Это огромная экономия, которая делает использование таких мощных моделей гораздо более доступным.
В общем, LLama-3.1-70B в динамической квантизации FP8 на 16K контекста на четырёх картах 4090 показала себя с лучшей стороны. Будем продолжать тестирование и оптимизацию, чтобы добиться ещё лучших результатов.
Прикладываю картинки:
1-2. Запуск на 4 4090 и нагрузка на сервер и его конфиги.
3. Тесты модели при проверке реранжирования.
Хочу поделиться своими последними успехами в работе с LLama-3.1-70b в тему предыдущего поста
Удалось запустить LLama-3.1-70B в динамической квантизации FP8 на 16K контекста, и самое главное, это получилось сделать на четырёх картах 4090. Это круто, учитывая все заморочки с памятью и настройками и выделением места под кэш.
Но не всё было так гладко с самого начала. Когда я только начинал запускать модель, возникли проблемы с p2p конфигом, который создавался криво. Плюс, Ray бекенд для выполнения модели на нескольких карточках тоже не сразу заработал как надо. Я долго не мог понять, почему при 96 GB VRAM у меня не влезало больше 6K контекста. Это было реально грустно и не понятно.
После трёх или четырёх дней тестов и экспериментов я наконец-то нашёл оптимальный конфиг для запуска модели. Это было непросто, но результат того стоил.
Проведя кучу тестов по нашим RAG доменам, я понял, что текущий тест выбивает 100% точность, что делает его невалидным. Придётся придумать новый тест для более точной оценки.
Что касается возможностей модели, вот что мы проверили:
1. Обобщение текстов: Модель отлично справляется, точно следуя контексту.
2. Разметка текста: Тесты по разметке и NER (Named Entity Recognition) показали улучшение точности на 10-25%.
3. Работа в режиме агента с tool_use: Модель показала высокую эффективность, особенно при запоминании seed и 0 температуре, ошибка на тесте вызове тулзов составила 0 на 100 примерах запросов.
Также оценили работу модели re-ranking. В 9 из 10 случаев модель давала адекватную оценку релевантности чанков до и после реранжирования в RAG подходе.
Производительность модели оказалась следующей:
- Чтение: Средняя скорость обработки prompt — 1418.7 токенов в секунду, средняя скорость генерации — 0.5 токенов в секунду. Использование GPU KV cache — 34.4%
- Генерация: Средняя скорость обработки prompt — 0.0 токенов в секунду, средняя скорость генерации — 36.0 токенов в секунду. Использование GPU KV cache — 35.1%
Эти данные показывают, что нам ещё нужно искать подходы для ускорения генерации, чтобы добиться более высокой производительности.
И вот самое приятное: теперь сервер стоит не 1,5 миллиона рублей в месяц, а всего 240 тысяч рублей! Карл, это в 6 раз дешевле! Это огромная экономия, которая делает использование таких мощных моделей гораздо более доступным.
В общем, LLama-3.1-70B в динамической квантизации FP8 на 16K контекста на четырёх картах 4090 показала себя с лучшей стороны. Будем продолжать тестирование и оптимизацию, чтобы добиться ещё лучших результатов.
Прикладываю картинки:
1-2. Запуск на 4 4090 и нагрузка на сервер и его конфиги.
3. Тесты модели при проверке реранжирования.
BY Neural Deep
Share with your friend now:
tgoop.com/neuraldeep/1013