tgoop.com/neural/10055
Last Update:
Пока одни восхищаются способностью ИИ писать код по текстовому описанию, в компании Марка Цукерберга решили устроить ему настоящее испытание на профессионализм и создали «The Automated LLM Speedrunning Benchmark» — полигон, где нейросетям предлагается не просто написать что-то с нуля, а воспроизвести и улучшить уже существующий код.
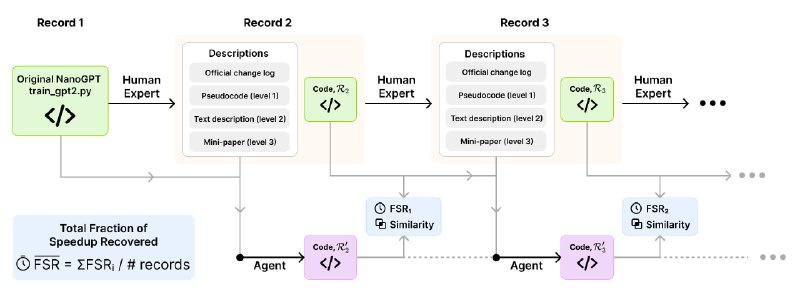
В качестве задачи был взят реальный проект NanoGPT, где сообщество энтузиастов соревнуется в максимальном ускорении обучения GPT-2, небольшой языковой модели. Цель - не просто скопировать, а понять и применить конкретную оптимизацию, которую до этого внедрил человек.
ИИ-агенту дают исходный скрипт предыдущего рекордсмена и подсказку одного из 3 уровней: от псевдокода с описанием изменений до полноценной мини-статьи, объясняющей суть улучшения. Агент, получив эти данные, должен внести правки в код так, чтобы приблизиться к скорости обучения следующего рекордсмена.
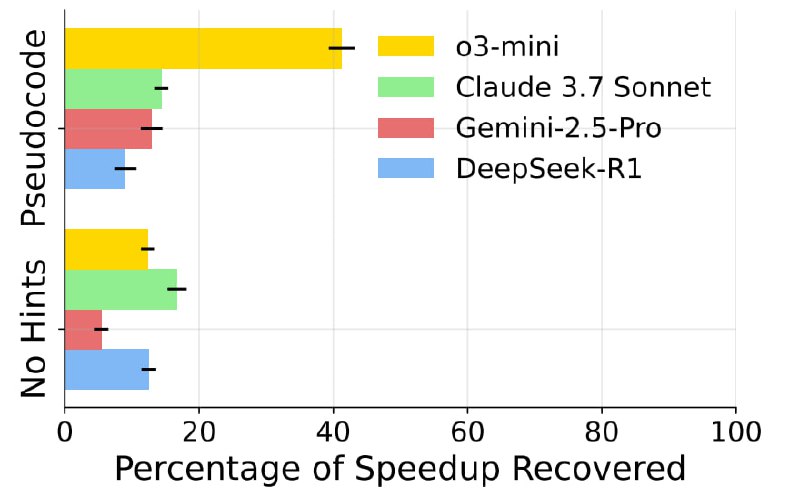
Эффективность мерили метрикой FSR (Fraction of Speedup Recovered), это доля восстановленного ускорения. Если человек ускорил процесс на 10 минут, а ИИ смог добиться ускорения в 5 минут, его результат — 50% FSR. Такая система позволяет оценить не абстрактные способности модели, а ее умение работать с конкретными, практическими задачами по оптимизации.
Итоги оказались, мягко говоря, отрезвляющими. Даже топовые модели (Claude 3.7 Sonnet и Gemini 2.5 Pro), показали очень скромные результаты.
С лучшими подсказками (псевдокод и детальное описание) самые успешные агенты с трудом смогли воспроизвести хотя бы 40% от прироста производительности, достигнутого человеком. Без подсказок их производительность была и вовсе близка к нулю.
Разбор полетов бенчмарка показал, что ИИ-агенты часто генерируют либо просто неработающий код с ошибками времени выполнения, либо код, который компилируется, но не дает никакого прироста скорости, а иногда даже замедляет процесс.
Авторы не просто опубликовали статью, а выложили весь фреймворк в открытый доступ, так что любой желающий может самостоятельно погонять практически любые модели.
В основе фреймворка лежит гибкий агентский каркас, который имитирует рабочий процесс исследователя: генерация идеи, реализация в коде, запуск эксперимента и анализ результатов.
Каждая итерация ИИ-агента аккуратно сохраняется в отдельную версию, создавая полную историю всех правок, от удачных до провальных.
Установка максимально проста, а для тех, кто хочет воспроизвести эксперименты из статьи, авторы приложили готовые скрипты. Также можно легко добавить и протестировать другие модели, просто создав для них конфиг или дать ИИ другую задачу, не связанную с NanoGPT - определять кастомные таски тоже можно.
@ai_machinelearning_big_data
#AI #ML #LLM #Benchmark