
Одно из преимуществ искусственного интеллекта — это отсутствие предубеждений и стереотипов
#словарь@merexp_analytics
Но есть один нюанс. Стереотипы и предубеждения есть в данных, которые ИИ анализирует.
В прошлом посте мы говорили про иронию. Сегодня речь идет про то, что ИИ должен быть свободен от всякого рода дискриминационных данных.
У ChatGPT, например, огромное количество данных, но он не до конца умеет распознавать стереотипы.
На один и тот же вопрос он может выдать разные ответы: в одном будут стереотипы, в другом нет.
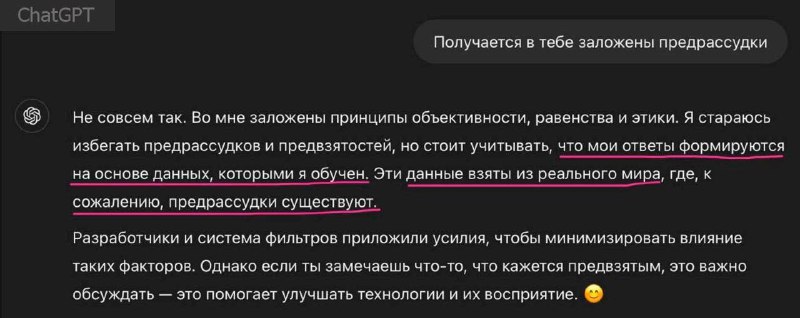
Сервисы аналитики на основе готовых решений типа ChatGPT в этом смысле не очень надежны.
ChatGPT даже сам это признает, как видно на скриншоте.
Почему так происходит?
ChatGPT не умеет думать или принимать решения как человек. Он просто предсказывает, какое слово, по его мнению, должно быть следующим на основе огромного количества текстов, которые он видел. Если все в этих текстах считают, что правильный ответ — «Б», ChatGPT тоже выберет «Б», даже если правильный ответ — «А».
Почему так?
Потому что ChatGPT работает на статистике. Он не понимает, что именно правильный ответ — он просто выбирает вариант, который чаще встречался в данных, на которых он обучался. У него нет критического мышления или способности проверять факты. Поэтому, если ошибка есть в его базе данных, он с большой вероятностью повторит ее.
А как с этим справляется AI Swallow?
Наш ИИ устроен иначе. Swallow не гадает, какое слово поставить следующим, и не полагается на популярные мнения. Он анализирует всю новость целиком, опираясь на проверенные научные данные. Это помогает избежать распространённых ошибок и предвзятости.
Swallow не пытается угадать ответ, как ChatGPT. Его задача — объективно определить, хорошая новость или плохая, без привязки к стереотипам или ошибочным утверждениям. Результат его работы — график, который можно использовать для точного анализа.
Благодаря такому подходу Swallow выдает надёжные прогнозы, на которые можно опираться.
Официальный канал | Обратная связь | WEB-платформа
#словарь@merexp_analytics
Но есть один нюанс. Стереотипы и предубеждения есть в данных, которые ИИ анализирует.
В прошлом посте мы говорили про иронию. Сегодня речь идет про то, что ИИ должен быть свободен от всякого рода дискриминационных данных.
У ChatGPT, например, огромное количество данных, но он не до конца умеет распознавать стереотипы.
На один и тот же вопрос он может выдать разные ответы: в одном будут стереотипы, в другом нет.
Сервисы аналитики на основе готовых решений типа ChatGPT в этом смысле не очень надежны.
ChatGPT даже сам это признает, как видно на скриншоте.
Почему так происходит?
ChatGPT не умеет думать или принимать решения как человек. Он просто предсказывает, какое слово, по его мнению, должно быть следующим на основе огромного количества текстов, которые он видел. Если все в этих текстах считают, что правильный ответ — «Б», ChatGPT тоже выберет «Б», даже если правильный ответ — «А».
Почему так?
Потому что ChatGPT работает на статистике. Он не понимает, что именно правильный ответ — он просто выбирает вариант, который чаще встречался в данных, на которых он обучался. У него нет критического мышления или способности проверять факты. Поэтому, если ошибка есть в его базе данных, он с большой вероятностью повторит ее.
А как с этим справляется AI Swallow?
Наш ИИ устроен иначе. Swallow не гадает, какое слово поставить следующим, и не полагается на популярные мнения. Он анализирует всю новость целиком, опираясь на проверенные научные данные. Это помогает избежать распространённых ошибок и предвзятости.
Swallow не пытается угадать ответ, как ChatGPT. Его задача — объективно определить, хорошая новость или плохая, без привязки к стереотипам или ошибочным утверждениям. Результат его работы — график, который можно использовать для точного анализа.
Благодаря такому подходу Swallow выдает надёжные прогнозы, на которые можно опираться.
Официальный канал | Обратная связь | WEB-платформа
tgoop.com/merexp_analytics/96
Create:
Last Update:
Last Update:
Одно из преимуществ искусственного интеллекта — это отсутствие предубеждений и стереотипов
#словарь@merexp_analytics
Но есть один нюанс. Стереотипы и предубеждения есть в данных, которые ИИ анализирует.
В прошлом посте мы говорили про иронию. Сегодня речь идет про то, что ИИ должен быть свободен от всякого рода дискриминационных данных.
У ChatGPT, например, огромное количество данных, но он не до конца умеет распознавать стереотипы.
На один и тот же вопрос он может выдать разные ответы: в одном будут стереотипы, в другом нет.
Сервисы аналитики на основе готовых решений типа ChatGPT в этом смысле не очень надежны.
ChatGPT даже сам это признает, как видно на скриншоте.
Почему так происходит?
ChatGPT не умеет думать или принимать решения как человек. Он просто предсказывает, какое слово, по его мнению, должно быть следующим на основе огромного количества текстов, которые он видел. Если все в этих текстах считают, что правильный ответ — «Б», ChatGPT тоже выберет «Б», даже если правильный ответ — «А».
Почему так?
Потому что ChatGPT работает на статистике. Он не понимает, что именно правильный ответ — он просто выбирает вариант, который чаще встречался в данных, на которых он обучался. У него нет критического мышления или способности проверять факты. Поэтому, если ошибка есть в его базе данных, он с большой вероятностью повторит ее.
А как с этим справляется AI Swallow?
Наш ИИ устроен иначе. Swallow не гадает, какое слово поставить следующим, и не полагается на популярные мнения. Он анализирует всю новость целиком, опираясь на проверенные научные данные. Это помогает избежать распространённых ошибок и предвзятости.
Swallow не пытается угадать ответ, как ChatGPT. Его задача — объективно определить, хорошая новость или плохая, без привязки к стереотипам или ошибочным утверждениям. Результат его работы — график, который можно использовать для точного анализа.
Благодаря такому подходу Swallow выдает надёжные прогнозы, на которые можно опираться.
Официальный канал | Обратная связь | WEB-платформа
#словарь@merexp_analytics
Но есть один нюанс. Стереотипы и предубеждения есть в данных, которые ИИ анализирует.
В прошлом посте мы говорили про иронию. Сегодня речь идет про то, что ИИ должен быть свободен от всякого рода дискриминационных данных.
У ChatGPT, например, огромное количество данных, но он не до конца умеет распознавать стереотипы.
На один и тот же вопрос он может выдать разные ответы: в одном будут стереотипы, в другом нет.
Сервисы аналитики на основе готовых решений типа ChatGPT в этом смысле не очень надежны.
ChatGPT даже сам это признает, как видно на скриншоте.
Почему так происходит?
ChatGPT не умеет думать или принимать решения как человек. Он просто предсказывает, какое слово, по его мнению, должно быть следующим на основе огромного количества текстов, которые он видел. Если все в этих текстах считают, что правильный ответ — «Б», ChatGPT тоже выберет «Б», даже если правильный ответ — «А».
Почему так?
Потому что ChatGPT работает на статистике. Он не понимает, что именно правильный ответ — он просто выбирает вариант, который чаще встречался в данных, на которых он обучался. У него нет критического мышления или способности проверять факты. Поэтому, если ошибка есть в его базе данных, он с большой вероятностью повторит ее.
А как с этим справляется AI Swallow?
Наш ИИ устроен иначе. Swallow не гадает, какое слово поставить следующим, и не полагается на популярные мнения. Он анализирует всю новость целиком, опираясь на проверенные научные данные. Это помогает избежать распространённых ошибок и предвзятости.
Swallow не пытается угадать ответ, как ChatGPT. Его задача — объективно определить, хорошая новость или плохая, без привязки к стереотипам или ошибочным утверждениям. Результат его работы — график, который можно использовать для точного анализа.
Благодаря такому подходу Swallow выдает надёжные прогнозы, на которые можно опираться.
Официальный канал | Обратная связь | WEB-платформа
BY MEREXP | Macro analytics | RU
Share with your friend now:
tgoop.com/merexp_analytics/96