JUDGE DECODING - новая вариация Спекулятивного Декодинга от Gen AI команды Ⓜ️ может ускорить инференс модели в 9X разСтатья📍TL;DR Вариация Speculative Decoding (SD) с Target и Draft моделями. Вместо верификации через совпадение вероятностей, как в классическом SD, используется оценка качества токенов в контексте - идея вдохновлена подходом LLM-as-a-judge. На паре моделей Llama 3.1 405B / 8B удаётся достичь впечатляющего ускорения в 9× (против ~2× у обычного SD) без потерь в качестве. Для запуска метода под свою задачу потребуется собрать немного качественных данных и провести разметку.
📍Интро. Классический Speculative Decoding работает так: маленькая и быстрая, но менее точная Draft модель авторегрессионно генерирует M токенов, после чего большая и медленная, но очень умная Target модель параллельно проверяет их. Токен принимается, если все предыдущие были приняты и вероятность от Target превышает вероятность от Draft с учётом случайного порога. В худшем случае сгенерируем только один токен. Если что, интуитивный
гайд про SD.
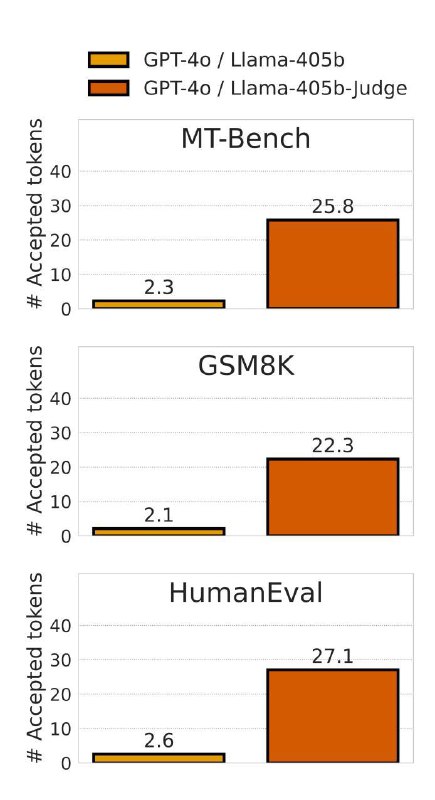
📍Инсайт. Схема верификации в стандартном SD учитывает только то, насколько вероятности draft токенов совпадают (align) с вероятностными оценками target модели. А контекстная корректность (или качество) самих токенов игнорируется. Поэтому на практике потолок accepted токенов в самом лучшем случае 6-7, а реально около 2. В статье проводят интересный эксперимент, чтобы исследовать эту гипотезу. Берут заведомо мощную большую draft модель, GPT-4o и target LLama-405B. Так как доступа к logit-ам draft-а нет, то используется Greedy Decoding. В итоге наблюдаем acceptance rate в районе 2 токенов. (картинка 1, первый столбик). Делают еще один эксперимент где в качестве draft-а высококачественные тексты написанные людьми. Результаты такие же - примерно 3 токена (картинка 2, первый столбик).
🔘Вывод - качество ответов draft-а не увеличивает acceptance rate. Поэтому хочется научиться как-то оценивать качество токенов, чтобы не отклонять слишком много полезных. Нужно найти источник полезного сигнала о draft токенах в target модели.
📍Суть метода. Собирают датасет из вопросов публичных датасетов(ARC, Alpaca). Дальше генерируют к этим вопросам правильные и неправильные ответы разными моделями (и Mistral-ями, и Llam-ами). Затем проверяют пары (question, response) вручную. Для каждого правильного ответа помечают все токены в ответе единичками. А в неправильных ответах помечают токены единичками до тех пор, пока не начинается генерация ошибочных токенов, их помечают уже ноликами. Таким путем собрали датасет из 500 пар с маской правильных/неправильных токенов.
Затем, обучают линейный слой для классификации токенов правильный/неправильный на основе эмбеддингов последнего слоя Llama 405B (она будет target моделью) на собранном датасете. Отсюда и возникает “Judge” в названии статьи - этот линейный слой во время инференса будет определять принять токен или отклонить. Так как эмбеддинг контекстный, то отсюда и получаем учет качества токенов.
📍Как устроен инференс. Как и в обычном SD генерируют M токенов draft моделью. Валидируют токены target моделью. Запускают judge голову и одновременно ванильный верификатор из классического SD. Получаем две маски из M токенов. Применяем Логическое “OR” и получаем итоговую маску принятых токенов (Картинка 3). Может возникнуть вопрос, почему OR, а не AND. Показывают, что изредка может произойти так, что классический SD принял токен, а Judge голова - нет. Все потому что Judge слой оптимизирован на минимизацию False Positives. Но так как Target модель в любом случае приняла бы этот токен, нет смысла обрубать принятие токенов на этом шаге.
📍Результаты. Замеряют скорость для пары LLama 405B / 8B, получают acceptance rate ~20 токенов, транслируется в 9X ускорение инференса при запуске из HF (картинка 4). Так как метод декодирования может внести регрессию в качество ответов, то отдельно репортят метрики качества на бенчмарках. Получают почти полный паритет с инференсом без draft модели.
#статья
@max_dot_sh