Увеличиваем контекстное окно LLM с 128K до 4M: разбор рецепта от 💻СтатьяTL;DR Авторы предлагают двухстадийный пайплайн дообучения Instruct-tuned LLM для увеличения длины контекста. Берут Llama 3.1 8B instruct c контекстным окном 128К и дообучают своим методом до нового окна на 1M, 2M или 4M. Показывают, что модель сохраняет качество на исходных бенчмарках, и становится сильно лучше на long-context задачах. На Needle in a Haystack бенчмарке показывает 100% accuracy на всех видах запросов. Бенчмарк синтетический и перестал быть показательным. На более реалистичных задачах из InfiniteBench, LV-Eval цифры сильно скромнее, не больше 30%, но лучше сравниваемых бейзлайнов. В бейзлайнах другие методы расширения контекста для Llama 3.1 8B.
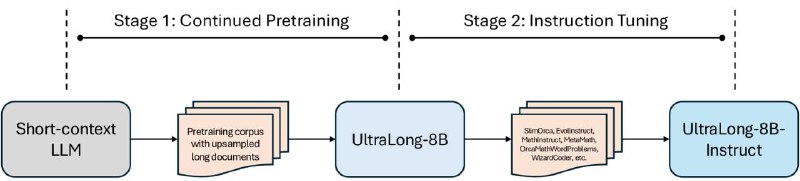
🔘В чем суть подхода? Берут обученную Llama 3.1 8B instruct. Первая стадия: увеличивают контекстное окно до целевого значения (1M, 2M или 4M) через дообучение (continued pretraining) на корпусе очень длинных документов и экстраполяции RoPE эмбеддингов. Вторая стадия: делают SFT на бленде из разных качественных датасетов. Картинка 1 иллюстрирует пайплайн. Разберем детали ниже.
🔘Как именно увеличивают длину контекстного окна? Все начинается с данных. Детали датасета для continued pretaining не раскрываются. Сэмплируют из проприетарного датасета длинные документы с оверсэмплингом длинных, больше 8K токенов. Получают корпус на 1B токенов. Документы конкатенируют, так, чтобы получить желаемую целевую длину контекста (1M, 2M, или 4M). При конкатенации документы разделяют специальным сепаратором, а не стандартными begin_of_text, end_of_text токенами. Делают ablation study, который показывает, что специальный сепаратор играет важную роль и растит качество. Так же, во время дообучения attention механизм видит всю последовательность (нет cross-document attention маски).
Наконец, используют метод
YaRN для модификации расчета RoPE эмбеддингов. Если коротко, то добавляют scaling factor, L’ / L, где L - максимальная поддерживаемая контекстная длина, а L’ - новая целевая длина и модифицируют расчет θ для интерполяции на новую длину.
🔘Что входит в Instruction Tuning? Собрали датасет на 100K насэмплировав примеров из открытых датасетов. Примеры в основном из трех категорий: общие знания (из ShareGPT, GPTeacher, и другие), код (WizardCoder), математика (MathInstruct, MetaMath). Часть ответов для промптов была нагенерирована с помощью GPT-4o. Далее делали SFT. Интересно, что на этой стадии никак не фильтровали данные по длине и не добавляли long context синтетики, большинство примеров < 8K. Тем не менее этого достаточно, чтобы “восстановить” reasoning навыки и instruct способности модели после увеличения контекста в первой стадии.
Авторы отмечают, что в будущем хотят попробовать RL-методы для второй стадии.
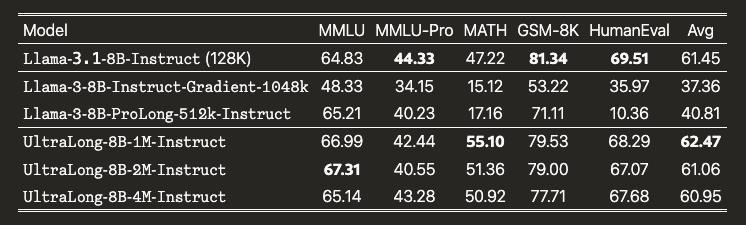
🔘Результаты. Так как брали предобученную модель и тюнили ее на длинный контекст, то измерять качество нужно на стандартных бенчмарках (чтобы убедиться, что нет деградации), и на специфичных для длинного контекста (чтобы померить эффективность метода). Метрики на общих бенчах в среднем на уровне базовой Llama 3.1 8B, либо чуть лучше. Картинка 2.
Теперь самое главное. Полезность длинного контекста.
Needle In A Hastack тест решает, в отличие от pretrained модели. Это хорошо. Но тест искусственный и в 2025 служит скорее sanity check адекватности, а не реальной оценки способностей. О том, что для моделей с длинным контекстом пора смотреть дальше обсуждалось и недавно
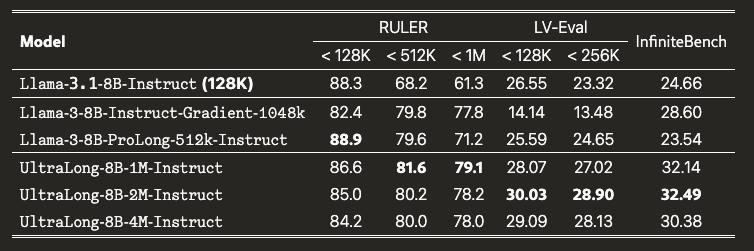
тут. На более реалистичных бенчмарках точность в среднем 30%. Например, авторы везде репортят InfiniteBench. В бенче есть задачи разные категорий, включая разные типа QA, суммаризации, арифметики и поиску кода на контекстах в среднем от 100K токенов. Новый метод обгоняет базовую модель (32% vs 24%) и в среднем лучше других бейзлайнов с поддержкой длинного контекста. На другом более прикладном бенче, LV-Eval результаты такие же. Несмотря на улучшения говорить о большой полезности длинного контекста через такой рецепт рано. Картинка 3.
💬 В комментариях оставил мнение по поводу работы в целом.
#статья
@max_dot_sh