
Forwarded from Machinelearning
⚡️ Ling-flash-2.0 теперь в открытом доступе! ⚡️
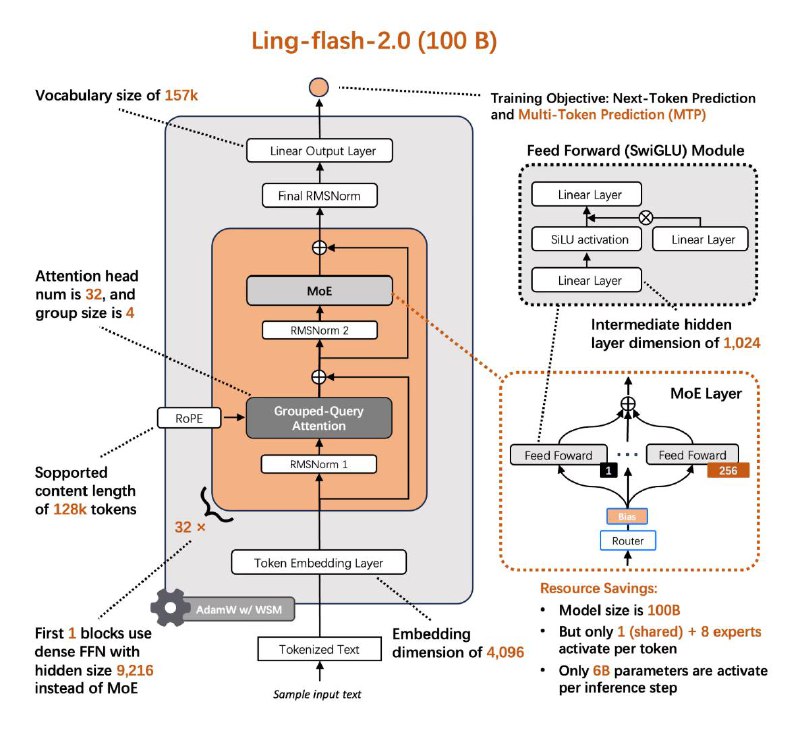
Модель на 100B параметров, но задействовано всего ≈6.1B активных, что делает модель очень экономной в вычислительной нагрузке.
🚀 Чем хороша Ling-flash-2.0
- Обучена на более чем 20 триллионах токенов с до-обучением и RL-этапами.
- Демонстрирует state-of-the-art производительность среди плотных моделей до 40B параметров.
- Особенно хороша в сложном рассуждении, генерации кода и задачах с фронтендом.
⚙️ Архитектура и эффективность
- MoE-архитектура с активированием лишь части параметров (activation ratio 1/32).
- Много технических фишек: продвинутое распределение экспертов, баланс внимания, схема маршрутизации без вспомогательных потерь и др.
- На железе H20 модель генерирует 200+ токенов в секунду - в 3× быстрее по сравнению с плотной моделью 36B.
- Поддерживает контексты до 128K токенов (с YaRN).
https://huggingface.co/inclusionAI/Ling-flash-2.0
@ai_machinelearning_big_data
#moe #llm #ml #ai #opensource
Модель на 100B параметров, но задействовано всего ≈6.1B активных, что делает модель очень экономной в вычислительной нагрузке.
🚀 Чем хороша Ling-flash-2.0
- Обучена на более чем 20 триллионах токенов с до-обучением и RL-этапами.
- Демонстрирует state-of-the-art производительность среди плотных моделей до 40B параметров.
- Особенно хороша в сложном рассуждении, генерации кода и задачах с фронтендом.
⚙️ Архитектура и эффективность
- MoE-архитектура с активированием лишь части параметров (activation ratio 1/32).
- Много технических фишек: продвинутое распределение экспертов, баланс внимания, схема маршрутизации без вспомогательных потерь и др.
- На железе H20 модель генерирует 200+ токенов в секунду - в 3× быстрее по сравнению с плотной моделью 36B.
- Поддерживает контексты до 128K токенов (с YaRN).
https://huggingface.co/inclusionAI/Ling-flash-2.0
@ai_machinelearning_big_data
#moe #llm #ml #ai #opensource
👍4❤2🔥2
tgoop.com/machinelearning_ru/2988
Create:
Last Update:
Last Update:
⚡️ Ling-flash-2.0 теперь в открытом доступе! ⚡️
Модель на 100B параметров, но задействовано всего ≈6.1B активных, что делает модель очень экономной в вычислительной нагрузке.
🚀 Чем хороша Ling-flash-2.0
- Обучена на более чем 20 триллионах токенов с до-обучением и RL-этапами.
- Демонстрирует state-of-the-art производительность среди плотных моделей до 40B параметров.
- Особенно хороша в сложном рассуждении, генерации кода и задачах с фронтендом.
⚙️ Архитектура и эффективность
- MoE-архитектура с активированием лишь части параметров (activation ratio 1/32).
- Много технических фишек: продвинутое распределение экспертов, баланс внимания, схема маршрутизации без вспомогательных потерь и др.
- На железе H20 модель генерирует 200+ токенов в секунду - в 3× быстрее по сравнению с плотной моделью 36B.
- Поддерживает контексты до 128K токенов (с YaRN).
https://huggingface.co/inclusionAI/Ling-flash-2.0
@ai_machinelearning_big_data
#moe #llm #ml #ai #opensource
Модель на 100B параметров, но задействовано всего ≈6.1B активных, что делает модель очень экономной в вычислительной нагрузке.
🚀 Чем хороша Ling-flash-2.0
- Обучена на более чем 20 триллионах токенов с до-обучением и RL-этапами.
- Демонстрирует state-of-the-art производительность среди плотных моделей до 40B параметров.
- Особенно хороша в сложном рассуждении, генерации кода и задачах с фронтендом.
⚙️ Архитектура и эффективность
- MoE-архитектура с активированием лишь части параметров (activation ratio 1/32).
- Много технических фишек: продвинутое распределение экспертов, баланс внимания, схема маршрутизации без вспомогательных потерь и др.
- На железе H20 модель генерирует 200+ токенов в секунду - в 3× быстрее по сравнению с плотной моделью 36B.
- Поддерживает контексты до 128K токенов (с YaRN).
https://huggingface.co/inclusionAI/Ling-flash-2.0
@ai_machinelearning_big_data
#moe #llm #ml #ai #opensource
BY Машинное обучение RU

Share with your friend now:
tgoop.com/machinelearning_ru/2988