tgoop.com/machinelearning_ru/2938
Last Update:
💡 Исследователи из ByteDance и Stanford предложили новый метод для генерации длинных видео — Mixture of Contexts.
🔑 В чём проблема:
Когда видео становится длинным, внимание модели сильно «раздувается»: растёт стоимость вычислений, модель теряет детали на генерациях, забывает персонажей и «дрейфует».
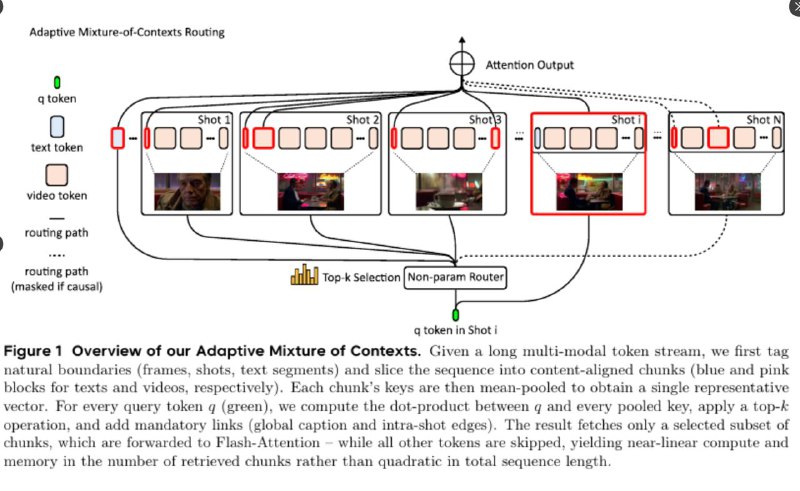
⚡ Чем интересен Mixture of Contexts:
- Видео разбивается на куски (кадры, шоты, подписи).
- Каждый запрос выбирает только нужные чанки, вместо того чтобы учитывать всю историю.
- Для этого используется простая оценка релевантности: сравнение признаков чанков с текущим запросом.
- Обязательно учитываются два «якоря»: полный текстовый промпт и локальный шот для деталей видео.
- Causal mask блокирует внимание к будущим кадрам, чтобы не было зацикливаний.
- Дальше применяется Flash Attention только к выбранным чанкам — вычисления растут не с длиной всего видео, а только с полезным контекстом.
📊 Результаты:
- В 7 раз меньше FLOPs
- В 2.2 раза быстрее работа
- На длинных сценах (180k токенов) отсекается 85% ненужного внимания
🎥 Итог:
- Короткие клипы сохраняют качество
- Длинные сцены становятся более плавными, а персонажи — стабильными
- Время генерации заметно сокращается
Главное: модель учится сама понимать, на что смотреть, получая «память» на минуты видео без изменения базовой архитектуры.
@ai_machinelearning_big_data
#AI #ML #ByteDance #Stanford #videogeneration