
tgoop.com/machinelearning_ru/2908
Last Update:
⚡ Новое исследование: меньше — значит лучше?
Авторы работы проверили, правда ли **Sparse Mixture of Experts (MoE)**-модели становятся лучше просто за счёт роста размера.
🔎 Сравнивали 8 открытых моделей на 10 бенчмарках в одинаковых условиях, проверяя результаты статистическими тестами.
Ключевые выводы
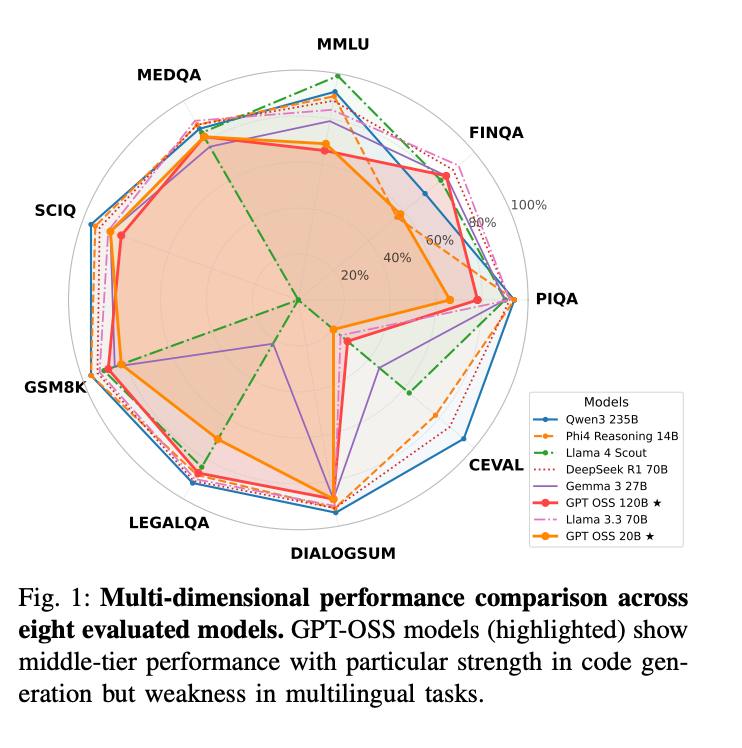
- 🏆 GPT-OSS 20B обошёл GPT-OSS 120B на MMLU и HumanEval.
- ⚡ 20B требует в 5 раз меньше GPU-памяти и на 2.6 раза меньше энергии на ответ.
- 20B даёт более короткие и точные ответы, а 120B часто проигрывает из-за неэффективного роутинга или обучения.
- Обе модели сильны в генерации кода, но слабы на китайских задачах.
Практическое значение
- ✅ Для английского кода и структурных рассуждений выгоднее использовать 20B — выше пропускная способность и ниже задержка.
- ❌ Для многоязычных и профессиональных доменов преимущества не так очевидны.
📄 Paper: arxiv.org/abs/2508.12461
BY Машинное обучение RU
Share with your friend now:
tgoop.com/machinelearning_ru/2908