tgoop.com/machinelearning_ru/2858
Last Update:
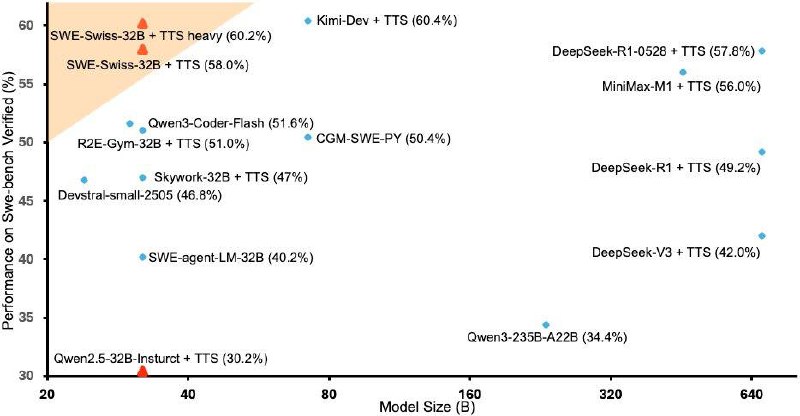
SWE‑Swiss-32B — модель с 32 млрд параметров, оптимизированная для эффективного исправления программных проблем.
Что входит в рецепт обучения:
- Мulti‑Task Fine‑Tuning + Reinforcement Learning — обучаем модель сразу на нескольких навыках и усиливаем через RL.
- Ключевые навыки:
- Локализация ошибок (файлы)
- Генерация патчей
- Создание unit-тестов
По результатам тестов на SWE‑bench Verified, модель показывает производительность на уровне передовых закрытых моделей, несмотря на свою среднюю размерность.
Плюсы:
- Доступно на Hugging Face под лицензией MIT
- Использует transformers — просто интегрировать в пайплайн
Почему это круто:
SWE‑Swiss — пример того, как грамотно комбинация мультизадочного обучения и RL позволяет добиться высоких результатов в решении понятийно сложных задач, делая LLM доступнее и эффективнее для разработчиков.
📑Notion: https://pebble-potato-fc6.notion.site/SWE-Swiss-A-Multi-Task-Fine-Tuning-and-RL-Recipe-for-High-Performance-Issue-Resolution-21e174dedd4880ea829ed4c861c44f88?pvs=143
💻Github: https://github.com/zhenyuhe00/SWE-Swiss